We have already written a few articles about Pylearn2. Today we’ll look at PyBrain. It is another Python neural networks library, and this is where similiarites end.
UPDATE: The modern successor to PyBrain is brainstorm, although it didn’t gain much traction as deep learning frameworks go.
They’re like day and night: Pylearn2 - Byzantinely complicated, PyBrain - simple. We attempted to train a regression model and succeeded at first take (more on this below). Try this with Pylearn2.
While there are a few machine learning libraries out there, PyBrain aims to be a very easy-to-use modular library that can be used by entry-level students but still offers the flexibility and algorithms for state-of-the-art research.
The library features classic perceptron as well as recurrent neural networks and other things, some of which, for example Evolino, would be hard to find elsewhere.
On the downside, PyBrain feels unfinished, abandoned. It is no longer actively developed and the documentation is skimpy. There’s no modern gimmicks like dropout and rectified linear units - just good ol’ sigmoid and tanh for a hidden layer.
It’s also slow, being written in pure Python. There’s an extension called ARAC that is supposed to make it run faster - still on a CPU though. We haven’t tried it and don’t know if it uses multicore.
There is also an independent project named cybrain, written in C but callable from Python. The author mentions 70x speed improvement.
Jrgen Schmidhuber
One of the reasons PyBrain is interesting is that the library comes from Jrgen Schmidhuber’s students. Two of them, Tom Schaul and Daan Wierstra, work for DeepMind, an AI company which was famously acquired by Google in January. One of the founders, Shane Legg, is also a former student of Jergen Schmidhuber.
The man is one of the leading authorities, if not the leading authority, on recurrent neural networks. He has been in the field for as long as Bengio and LeCunn: Schmidhuber was born in 1963, Bengio in 1964, LeCun in 1960 (Hinton is older, if you’re wondering: born 1947).
After watching the TED talk about explaining the universe we’re not sure if Schmidhuber is a genius or a madman. He’s certainly a showman - go on, take a look, he tells a joke in the beginning. In any case, his mind is far from average. You can get the vibe from visiting his page, on the net since 1405. It has more on the universe, beauty and other stuff.
A female face designed by J. Schmidhuber to be attractive. Source: Facial Beauty And Fractal Geometry
Here’s a relevant talk, The Algorithmic Principle Beyond Curiosity.
Data in, predictions out. How?
To get familiar with the library we will use kin8nm, a small regression benchmark dataset we tackled a few times before using various methods. A random forest produces RMSE of 0.14, RMSE of 0.1 is pretty good and 0.05 is as good as it gets. With PyBrain you can pretty quickly get 0.06 in validation with no parameter tuning. It’s almost like the authors chose default hyperparam values on the same dataset.
As usual, we need to figure out how to get the data in and predictions out. Neither part is well covered by the docs. About the first, they say how to provide one example at a time, whereas we’d like to load a matrix from a file and feed it wholesale. Here’s how to prepare a dataset:
ds = SupervisedDataSet( input_size, target_size )
ds.setField( 'input', x_train )
ds.setField( 'target', y_train )
Apparently Y needs to be of shape (n,1) as opposed to (n,), so first we reshape it:
y_train = y_train.reshape( -1, 1 )
And to train a network:
hidden_size = 100 # arbitrarily chosen
net = buildNetwork( input_size, hidden_size, target_size, bias = True )
trainer = BackpropTrainer( net, ds )
trainer.trainUntilConvergence( verbose = True, validationProportion = 0.15, maxEpochs = 1000, continueEpochs = 10 )
The trainer has a convenient method trainUntilConvergence. It automatically sets aside some examples for validation and is supposed to train until the validation error stops decreasing. The error fluctuates, so there’s the continueEpochs param which tells the trainer how many epochs to wait to get a new best score - stop otherwise. In our experiment the training went on for about 600 epochs.
Nothing gets printed while training, so we forked PyBrain and added error display after each epoch. It seems that the network doesn’t overfit, at least up to a point: training and validation errors went down hand in hand, training more steadily than validation though.
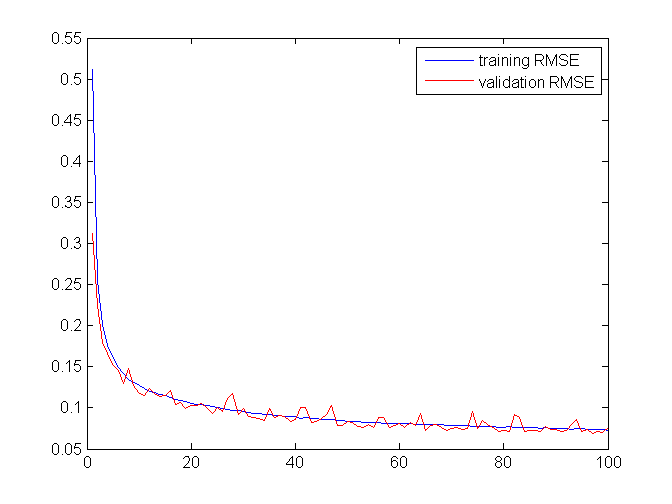
The first 100 epochs
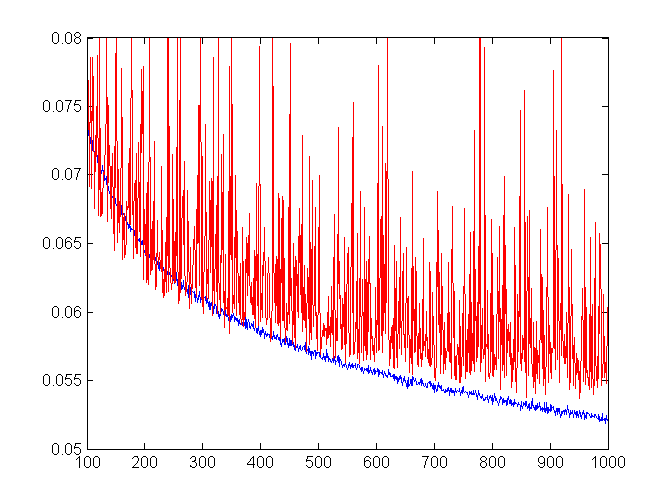
Epochs 100-1000
Predictions
Producing predictions, especially for regression tasks, seems to be also missing from the tutorial. Fortunately it’s easy:
p = net.activateOnDataset( ds )
Scores: around 0.08 from the model from the validation stage, 0.09 from the one trained on the full set. What’s going on here?
The code is available at GitHub. The data/ dir contains three files: train.csv, validation.csv and test.csv. That’s our custom split. Since trainUntilConvergence splits data for validation automatically, we join train and validation sets first.