Little Spearmint couldn’t sleep that night. I was so close… - he was thinking. It seemed that he had found a better than default value for one of the random forest hyperparams, but it turned out to be false. He made a decision as he fell asleep: Next time, I will show them!
The way to do this is to use a dataset that is known to produce lower error with high mtry values, namely previously mentioned Madelon from NIPS 2003 Feature Selection Challenge. Among 500 attributes, only 20 are informative, the rest are noise. That’s the reason why high mtry is good here: you have to consider a lot of features to find a meaningful one.
The dataset consists of a train, validation and test parts, with labels being available for train and validation. We will further split the training set into our train and validation sets, and use the original validation set as a test set to evaluate final results of parameter tuning.
As an error measure we use Area Under Curve, or AUC, which was one of the metrics in the original competition. By the way, it is still open to submissions. The original winners achieved 0.98 AUC on a test set (training on combined train and validation sets), and it’s still the best!
Colors again denote a validation error value (1 - AUC). This time we add red to mark the best results:
- red: error < 0.085
- green: error < 0.09
- blue: error < 0.10
- black: error >= 0.10
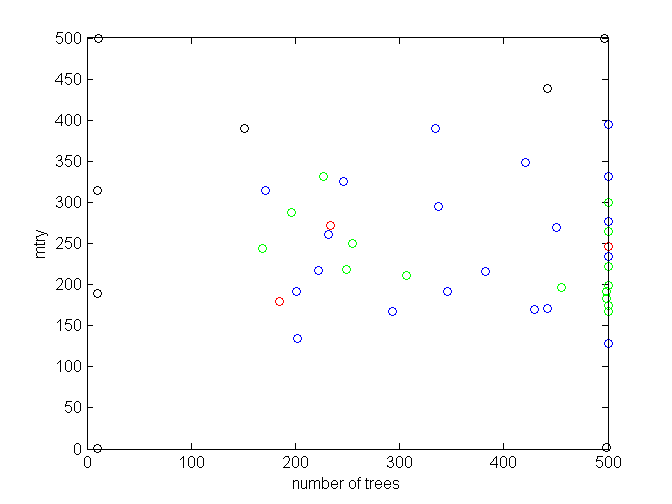
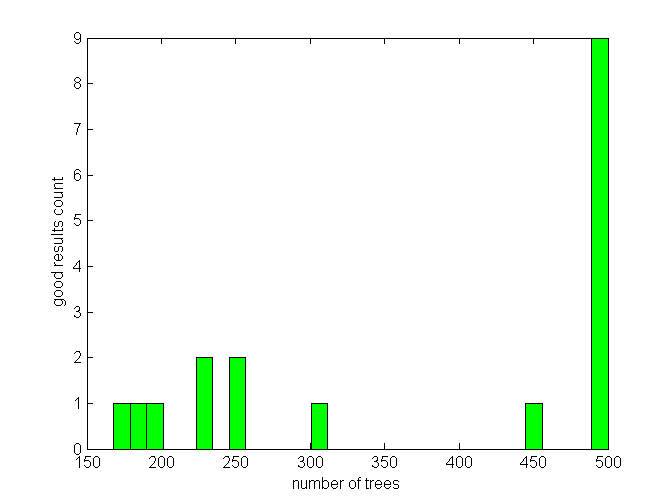
There seems to be an area in the vicinity of 200 trees that produces good results. But they are mixed with not so good ones there. We can also observe that 500 trees are promising. It can be seen on a histogram of good results (error < 0.09) vs. a number of trees they were achieved with:
In the second run we’ll explore the space between 500 and 1000 trees.

Clearly, mtry around 200 seems the best, regardless of a number of trees. Note that Spearmint is very sure about lower mtry values: it hardly explores any setting of less than 150.
As a special treat, we provide a visualization of Spearmint sniffing for low error. Colors are inverted, meaning that red signifies the highest error, blue the lowest. Some high-error points were removed to get a closer look at the error range.
You can adjust playback speed next to the progress slider. Note how in a few tries Spearmint catches a whiff of the “200” line and follows it, then does some more sniffing around.
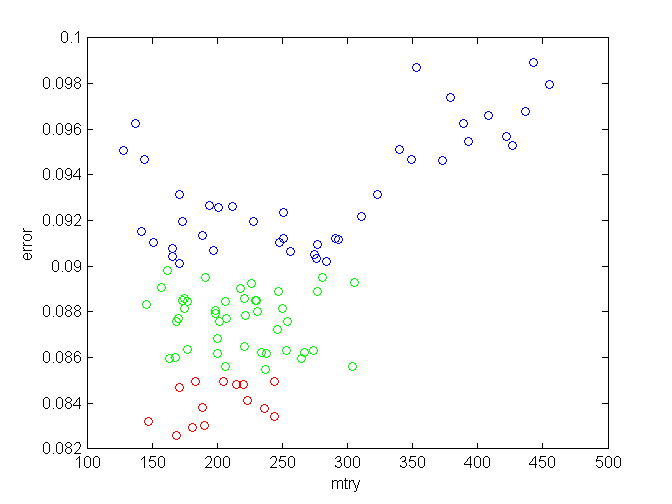
And finally, a plot of error vs. mtry which confirms that an optimal range for mtry is between 150 and 250:
The scores
The best result was 0.0826116 with 919 trees and mtry equal to 169. Let’s check the outcome on a proper validation set. We’ll train two random forests, both with 919 trees, one with with mtry = 169 and one with a default value.
Success, at last: AUC for the default setting is 0.825, and for the one we found 0.927. A big improvement!
We submitted our results on the competition page, and they scored 1.0 training, 0.9279 validation, 0.9285 test (search for Fastml.com on the scoreboard). Not enough to write home about, but a pretty good score. Subsequently we used combined training and validation sets for training, and scored 1.0 training and validation (no surprise here), 0.9336 test.
No errors on both training sets might suggest overfitting, especially so because there are a lot of people with higher test score than us, but only few with zero errors on training. It also suggests not to take the best found result literally. After inspecting the chart, we concluded we might be better off with a setting of (750, 222), for example. And indeed, it produces a higher score.
The code for tuning hyperparams, plotting and preparing submission files is available.
Maybe I’m good for something after all - little Spearmint was thinking as he cuddled his teddy bear to sleep.