The promise
What’s attractive in machine learning? That a machine is learning, instead of a human. But an operator still has a lot of work to do. First, he has to learn how to teach a machine, in general. Then, when it comes to a concrete task, there are two main areas where a human needs to do the work (and remember, laziness is a virtue, at least for a programmer, so we’d like to minimize amount of work done by a human):
- data preparation
- model tuning
This story is about model tuning.
Typically, to achieve satisfactory results, first we need to convert raw data into format accepted by the model we would like to use, and then tune a few hyperparameters of the model.
For example, some hyperparams to tune for a random forest may be a number of trees to grow and a number of candidate features at each split (mtry in R randomForest). For a neural network, there are quite a lot of hyperparams: number of layers, number of neurons in each layer (specifically, in each hidden layer), a learning rate and so on. Similarly for SVMs - consider command line options for libsvm:
Usage: svm-train [options] training_set_file [model_file]
options:
-s svm_type : set type of SVM (default 0)
0 -- C-SVC
1 -- nu-SVC
2 -- one-class SVM
3 -- epsilon-SVR
4 -- nu-SVR
-t kernel_type : set type of kernel function (default 2)
0 -- linear: u'*v
1 -- polynomial: (gamma*u'*v + coef0)^degree
2 -- radial basis function: exp(-gamma*|u-v|^2)
3 -- sigmoid: tanh(gamma*u'*v + coef0)
4 -- precomputed kernel (kernel values in training_set_file)
-d degree : set degree in kernel function (default 3)
-g gamma : set gamma in kernel function (default 1/num_features)
-r coef0 : set coef0 in kernel function (default 0)
-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)
-n nu : set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)
-p epsilon : set the epsilon in loss function of epsilon-SVR (default 0.1)
-m cachesize : set cache memory size in MB (default 100)
-e epsilon : set tolerance of termination criterion (default 0.001)
-h shrinking : whether to use the shrinking heuristics, 0 or 1 (default 1)
-b probability_estimates : whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)
-wi weight : set the parameter C of class i to weight*C, for C-SVC (default 1)
-v n: n-fold cross validation mode
-q : quiet mode (no outputs)
Tuning those parameters is a tedious job typically done by hand, or by relatively inefficient grid search. Enter Spearmint, a piece of software to automatically tune hyperparams. Now you can see the promise it offers.
We will concentrate on how to use it in practice, because a learning curve might be quite steep, even though the README is pretty good.
How it works
First, install Spearmint and Google Protocol Buffers. Protocol Buffers are only needed for a config file, you don’t need to bother yourself too much with them. Then run the braninpy example supplied in the original package. This will give you an idea of how things are supposed to work.
As a real life example, we will try to find an optimal value for just one hyperparam. In this case, a learning rate for a neural network. It so happens that this was one of the assignments in Geoffrey Hinton’s online class on neural networks. Also, prof. Hinton mentioned this very software, though not by a name, in the last unit.
There are two pieces to this puzzle: a config file and a wrapper file. In the config file, you define the hyperparams you would like to optimize, and provide some data about the wrapper file, namely a name and a language. Let’s say the language is PYTHON and the name is a4 (for assignment four). Spearmint will then know to call main() in a4.py.
The wrapper file works as a black box: Spearmint will pass to it hyperparams values in a Python dictionary and expects to get back a single number, which is a measure of optimality of those hyperparams.
An importal note: the format of params dictionary is not name: value, it’s name: [ value ] - each key points to a list of values. That’s because you can have as many actual params as you want under one name (it’s the size variable in config), and they are passed as a list. Strange, but conceivably useful in some situations. We will use just one param, so in our code we need to refer to the first element of the list: params['learning_rate'][0].
The main code is written in Matlab, while Spearmint is written in Python. There is a built-in solution to run Matlab files, but it’s quite hard to get it working with Octave, and we intend to use Octave. We tried, but after jumping a few hurdles we gave up. One of the Matlab files was referencing Java, so that was it.
We will just use another wrapper, this time to call an Octave file from Python. No big deal here, the script receives a learning rate value as a command line argument and then calls the proper function with the received parameter.
Then, the main neural network code will run and produce some text output. The output will contain a validation error value which we would like to be as low as possible. We catch the output, extract the value using a regular expression and pass it back to Spearmint.
In practice
The practice is pretty slow. This is a kind of thing you would leave running overnight. For each setting of a hyperparam, Spearmint has to train and validate. The best case scenario is a few tries. With one hyperparam, a learning rate for an RBM, we were able to get to the optimum in twelve tries. Below is a lucky chart. Notice that the error curve has a definitely convex shape and the software gets to the point pretty quickly.

You can monitor the progress with tail -f trace.csv. Unix utility tail shows an end of a file, and with -f option it continuously monitors a file for changes. Spearmint updates trace.csv every two seconds by default. Trace looks like this in the beginning, the values come from another run:
1354719550,nan,-1,20000,0,0
1354719552,nan,-1,19999,1,0
1354719554,nan,-1,19999,1,0
And after some time:
1354733975,0.213060,20118,19998,1,132
1354733977,0.213060,20118,19998,1,132
1354733979,0.211396,20130,19998,0,133
The first number is a timestamp, the second one - current best, then job id of best result. At the beginning these are nan (not a number) and -1, because we don’t have any results yet. The last number is tries made.
There is also /output directory with details for each job. We extracted data for charts from these files using a Python script, output2csv.py.
So far, so good. Now for not-so-good news. The chart above refers to optimizing log learning rate. First we tried optimizing the learning rate without taking a logartithm. Here’s the chart:
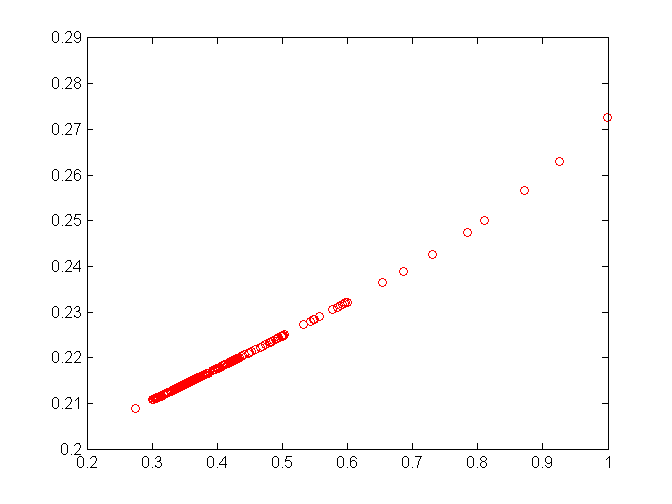
Something went wrong. Instead of exploring space to the left, where error is clearly lower, Spearmint focuses for some reason on 0.3 - 0.45 range. In other words, this run failed to even get close to the minimum. Only after switching to optimizing log rate everything went right.
That poses a potential problem, because when optimizing multiple parameters you won’t be able to plot the error hyperplane to validate it visually.
If you’re wondering, an apparent reason for this strange behaviour was a high error at the lower bound. A learning rate lies in a range of (0, 1), so we set the lower bound at 0.0001. Spearmint tries extremes first, and at the lower bound the error is high.

We deleted this point from previous charts to show the curve up close. One hypotesis is that Spearmint is unwilling to explore the space to the left because at the bound the error is so high. However, in another experiment this wasn’t a problem:
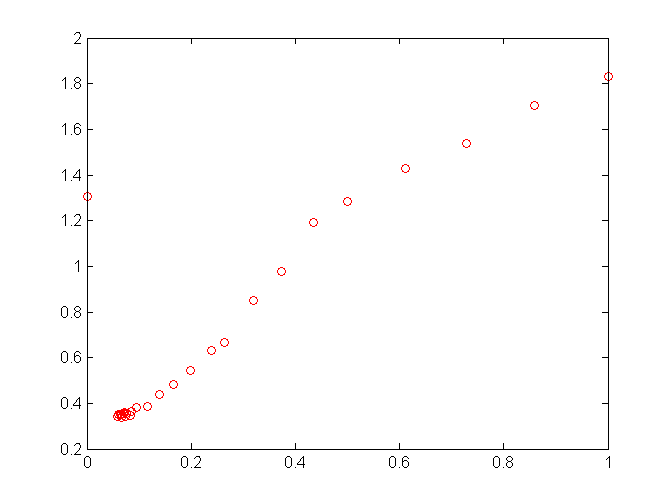
An apparent difference is that the error is higher at the upper bound than at the lower bound, and also in the shape of the error curve, which is not linear here. The program kept exploring the whole space, fortunately concentrating on the most promising range:
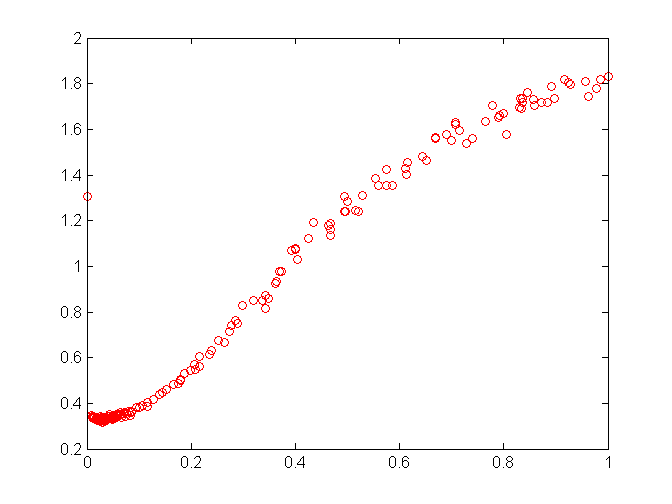
That’s pretty much all we know about the subject at the moment. More testing would be in order.
We would like to thank Jasper Snoek, the author of Spearmint, for help, and specifically for suggesting to optimize log rate.