In this article, we revisit Numerai and their weekly data science tournament. New developments include a much larger dataset, tougher requirements for models, and bigger payouts.
Let’s start with data. The training set has roughly half a million examples, each with 50 features. Then there’s validation, test, and live. Validation has labels, the rest don’t. Test is what Numerai use for their validation, presumably. An live is what matters.
The signal in the data is very week. Imagine you predict 0.5 for each example. Such prediction would score -ln( 0.5 ), or 0.693, as measured by log loss. 0.69 on live is good. 0.68 wins the tournament.
This doesn’t leave much room for creativity with modelling - it’s hard to beat logistic regression results.
Numerai crowd-sources predictions and ensembles them. When a few hundred people provide linear model predictions differing by n-th decimal digit, it’s no good for the fund. They need original submissions.
Besides originality, there are two other criteria which a contender must fulfil before entering the tournament proper. Recently, Numerai open-sourced code for all three. Thanks to that, we can understand the requirements better and check our predictions locally, which allows faster iterating.
Originality
For checking originality, Numerai chose the two-sample KolmogorovSmirnov test. It is intended to tell if two samples come from the same distribution. The idea is quite simple: one takes two sets of predictions and computes a cumulative distribution function for each. The biggest difference between the distributions becomes the KS statistic.
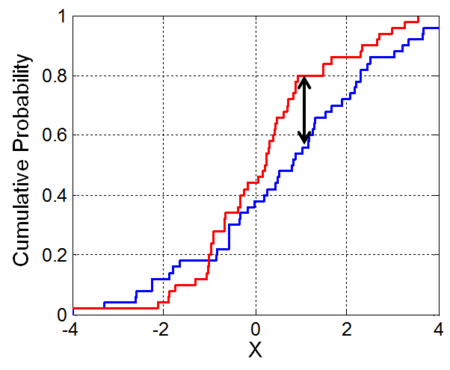
In practice, they compare your predictions to every other set of current predictions, and this process takes some time. If any of the resulting scores doesn’t clear a specific threshold, the submission is deemed unoriginal.
Complementing the originality score is Pearson correlation, which must be less than 0.95 for all pairs.
Of the three criteria, originality is the biggest hurdle to clear. As soon as the clock strikes midnight, there’s a rush to download new data. Modelling with a bunch of linear models take about 10 seconds, so those with the fastest internet connections win. There is an API, should you want to automate everything.
Still, in a given tournament, most people come up with original predictions.
Consistency
Your validation log loss score needs to be consistenly better than -ln(0.5), or 0.693. Now, what does it mean?
Each example in the training and validation sets has an attribute called era. An era is a marker of time and it allows measuring consistency. All eras are of similar size: roughly six thousand examples. Beyond that, not much is known about them.
Validation set contains 12 eras. If the predictions score better than -ln( 0.5 ) in at least eight eras, you’re good to go. In other words, 75% consistency on validation set is required.
For reference: at the moment, a basic logistic regression model achieves 7 good eras, that is, 7/12 = 58% consistency.
We provide code for checking consistency of your predictions. Here’s how you invoke it:
# we renamed numerai_tournament_data.csv to test.csv
$ ./check_consistency.py predictions/p.csv data/test.csv
loading predictions/p.csv...
loading data/test.csv...
era86 6091 69.06% True
era87 6079 68.61% True
era88 6067 69.28% True
era89 6064 69.12% True
era90 6050 68.90% True
era91 6027 69.22% True
era92 6048 69.85% False
era93 6038 69.34% False
era94 6326 68.94% True
era95 6349 68.88% True
era96 6336 69.23% True
era97 6390 69.31% True
consistency: 83.3% (10/12)
log loss: 69.14%
The script loads the predictions and the test file, which contains the validation set. Then it computes log loss for each validation era and from that, the consistency score. It also reports number of examples in each era and total validation log loss.
Concordance
Let’s say we can’t be bothered right now with all this consistency nonsense, so we just train with the validation set included. The labels are available, after all. This should solve our consistency problem. Fools, they shouldn’t have checked validation consistency anyway!
To discourage this behaviour, Numerai introduced the concordance metric. Concordance means that predictions should at least look like they come from the same distribution.
For testing this, they use the KolmogorovSmirnov statistic again. But instead of comparing sets of predictions, they apply k-means clustering to your set, then compare clusters, which should be “unoriginal”.
There have been some doubt about this particular method, but from our experiments with modifying predictions it appears to work.
The tournament

Here we go
With all three criteria fulfilled, you’re in play. The tournament lasts a week. After that, there are some fresh data points and the next tournaments starts.
However, the results for the previous tournament are known only after three further weeks. During this time, the models work on live data, and the live log loss score decides who gets paid. While you can see some fantastic validation scores, live scores rarely go below 0.69. Beware of overfitting the validation set.
A nice thing about payouts is that a hundred people get money, not just the top three or ten. Admittedly, the 50th contender gets $4.15 (in Ether) and 1.66 NMR. Still, better than nothing.
Government through numbers
Numerai makes all payouts in cryptocurrency, including their own, called Numeraire (NMR). It is worth attention because the main part of any award in the general tournament is paid in Numeraire. The winner gets meagre $400, plus 160 NMR, which at the rate of $15 per NMR is $2400.
A unique thing about NMR is that you can stake it on your predictions. If you are rather sure that you will score better than 0.693 on the live set, you can wager some NMR on it.
The payout is in dollars, at a rate you specify. This rate is called confidence. For example, when you stake 1 NMR with confidence of 0.1, you get $10 upon winning.
There is a catch: the pool for stake payouts is $6000 per tournament, and people with highest confidence predictions are paid first. One either wins and gets their money, or lose their NMR. When the pool is exhausted, everybody else just gets their NMR back. The details of staking are described in the whitepaper.
It is worth noting that in the main tournament, you want low live loss. When staking, however, what matters is consistency (in a general sense of model doing well every time). The score just needs to be marginally better than -ln(0.5).
Losing NMR are destroyed, which lowers the total supply. This is good, because otherwise the supply is steadily growing due to the payouts, lowering the exchange rate. In July, 1 NMR was worth $40, now it’s about $15 - see the chart. It makes one think about the asymptotical NMR price. Is there an equilibrium to be achieved?
If you’d like to know what the future might hold, check out the Numerais Master Plan, as outlined by the founder, Richard Craib.
For now, we stake 0.19*, comrade. The imperialist currency must be destroyed, and we’ll do it, bit by bit. We will make dollar great again, comrade!
* Not possible. The minimum stake is 1 NMR.