Numerai is an attempt at a hedge fund crowd-sourcing stock market predictions. It presents a Kaggle-like competition, but with a few welcome twists.
For one thing, the dataset is very clean and tidy. As we mentioned in the article on the Rossmann competition, most Kaggle offerings have their quirks. Often we were getting an impression that the organizers were making the competition unnecessarily convoluted - apparently against their own interests. It’s rather hard to find a contest where you could just apply whatever methods you fancy, without much data cleaning and feature engineering. In this tournament, you can do exactly that.
The task is binary classification. The dataset is low dimensional (14 continuous variables, one categorical, with cardinality of 23) and has a lot of examples, but not too many - 55k. All you need to do is create a validation set (an indicator column is supplied for that), take care of the categorical variable, and get cracking.
The metric for the competition is AUC. Normally, random predictions result in AUC of 0.5. The current leader scores roughly 0.55, which suggests that the stocks are a hard problem indeed, as our previous investigation indicated.
Stocks
Well-known, mainstream approaches concentrate on predicting asset volatility instead of prices. Predicting volatility allows to value options using the famous Black-Scholes formula. No doubt there are other techniques, but for obvious reasons people aren’t very forthcoming with publishing them. One insider look confirms that algorithmic learning works and people make tons of money - until the models stop working.
Numerai’s solution to this problem is to crowdsource the construction of models. All they want is predictions.
We have invented regularization techniques that transform the problem of capital allocation into a binary classification problem. (…) Recently, breakthrough developments in encryption have made it possible to conceal information but also preserve structure. (…) Were buying, regularizing and encrypting all of the financial data in the world and giving it away for free.
Well, you sure can download the dataset without registering. Still no idea what it represents, but it doesn’t stop you from placing on the leaderboard with a good black-box model. From Richard Craib, the Numerai founder:
I worked at a big fund. They wanted to kill me when I proposed running a Kaggle competition. Then I started learning about encryption and quit to start my own Kaggle inspired hedge fund.
Getting back to the comparisons with Kaggle, there are a few more differences about the logistics. More people get the money - the whole top 10. Also, the payouts will be recurring. This is good news: if you find yourself near the top of the leaderboard and stay there, the rewards will keep flowing. We hear that they might increase if the Numerai hedge fund goes up.
Let’s dive in, then. We have prepared a few Python scripts that will get you started with validation and prediction.
UPDATE: Logistic regression code for march 2016 data.
The validation split
As we mentioned, each example has a validation flag, because even though the points look independent, the underlying data has a time dimension. The split is set up so that you don’t use data “from the future” in training.
d = pd.read_csv( 'numerai_training_data.csv' )
# indices of validation examples
iv = d.validation == 1
val = d[iv].copy()
train = d[~iv].copy()
# no need for the column anymore
train.drop( 'validation', axis = 1 , inplace = True )
val.drop( 'validation', axis = 1 , inplace = True )
In our experiments we found that cross-validation produces scores very simlilar to the predefined split, so you don’t have to stick with it.
Encoding the categorical variable
The next thing to do is encoding the categorical variable. Let’s take a look.
In [5]: data.groupby( 'c1' )['c1'].count()
Out[5]:
c1
c1_1 1356
c1_10 3358
c1_11 2339
c1_12 367
c1_13 74
c1_14 5130
c1_15 3180
c1_16 2335
c1_17 1501
c1_18 1552
c1_19 1465
c1_20 2944
c1_21 1671
c1_22 1858
c1_23 2373
c1_24 2236
c1_3 10088
c1_4 2180
c1_5 2640
c1_6 1112
c1_7 1111
c1_8 3182
c1_9 986
Name: c1, dtype: int64
We replace the original feature with dummy (indicator) columns:
train_dummies = pd.get_dummies( train.c1 )
train_num = pd.concat(( train.drop( 'c1', axis = 1 ), train_dummies ), axis = 1 )
val_dummies = pd.get_dummies( val.c1 )
val_num = pd.concat(( val.drop( 'c1', axis = 1 ), val_dummies ), axis = 1 )
Of course it doesn’t hurt to check if the set of unique values is the same in the train and test sets:
assert( set( train.c1.unique()) == set( val.c1.unique()))
If it weren’t, we could create dummies before splitting the sets.
Training
And we’re done with pre-processing. At least when using trees, which don’t care about column means and variances. For other supervised methods, especially neural networks, we’d probably want to standardize - see the appendix below.
Training a random forest with 1000 trees results in validation AUC of roughly 52%. On the leaderboard, it becomes 51.8%.
Now you can proceed to stack them models like crazy.
UPDATE: This tournament also has a nasty quirk - validation scores didn’t reflect the leaderboard score. It resulted in a major re-shuffle in the final standings. Interestingly, seven of the top-10 contenders stayed in top-10, while the rest tumbled down.
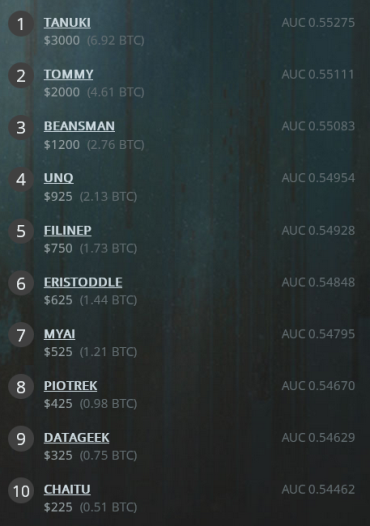
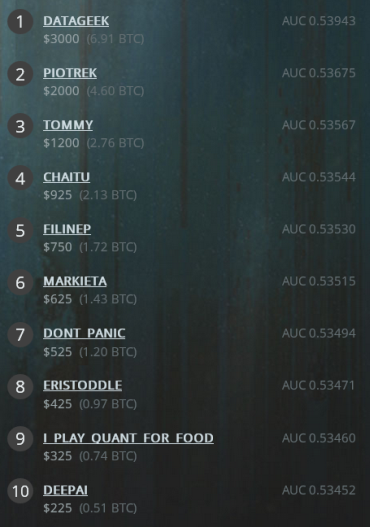
Before and after.
Appendix: transforming data with scikit-learn
Scikit-learn provides a variety of scalers, a row normalizer and other nifty gimmicks. We’re going to try them out with logistic regression. To avoid writing the same thing many times, we first define a function that takes data as input, trains, predicts, evaluates, and returns scores:
def train_and_evaluate( y_train, x_train, y_val, x_val ):
lr = LR()
lr.fit( x_train, y_train )
p = lr.predict_proba( x_val )
p_bin = lr.predict( x_val )
acc = accuracy( y_val, p_bin )
auc = AUC( y_val, p[:,1] )
return ( auc, acc )
Then it’s time for…
Transformers
![]()
We create a wrapper around train_and_evaluate() that transforms X’s before proceeding. This time we use global data to avoid passing it as arguments each time:
def transform_train_and_evaluate( transformer ):
global x_train, x_val, y_train, y_val
x_train_new = transformer.fit_transform( x_train )
x_val_new = transformer.transform( x_val )
return train_and_evaluate( y_train, x_train_new, y_val, x_val_new )
Now let’s iterate over transformers:
transformers = [ MaxAbsScaler(), MinMaxScaler(), RobustScaler(), StandardScaler(),
Normalizer( norm = 'l1' ), Normalizer( norm = 'l2' ), Normalizer( norm = 'max' ),
PolynomialFeatures() ]
for transformer in transformers:
print transformer
auc, acc = transform_train_and_evaluate( transformer )
print "AUC: {:.2%}, accuracy: {:.2%} \n".format( auc, acc )
We can also combine transformers using Pipeline, for example create quadratic features and only then scale:
poly_scaled = Pipeline([( 'poly', PolynomialFeatures()), ( 'scaler', MinMaxScaler())])
transformers.append( poly_scaled )
The output:
No transformation
AUC: 52.67%, accuracy: 52.74%
MaxAbsScaler(copy=True)
AUC: 53.52%, accuracy: 52.46%
MinMaxScaler(copy=True, feature_range=(0, 1))
AUC: 53.52%, accuracy: 52.48%
RobustScaler(copy=True, with_centering=True, with_scaling=True)
AUC: 53.52%, accuracy: 52.45%
StandardScaler(copy=True, with_mean=True, with_std=True)
AUC: 53.52%, accuracy: 52.42%
Normalizer(copy=True, norm='l1')
AUC: 53.16%, accuracy: 53.19%
Normalizer(copy=True, norm='l2')
AUC: 52.92%, accuracy: 53.20%
Normalizer(copy=True, norm='max')
AUC: 53.02%, accuracy: 52.66%
PolynomialFeatures(degree=2, include_bias=True, interaction_only=False)
AUC: 53.25%, accuracy: 52.61%
Pipeline(steps=[
('poly', PolynomialFeatures(degree=2, include_bias=True, interaction_only=False)),
('scaler', MinMaxScaler(copy=True, feature_range=(0, 1)))])
AUC: 53.62%, accuracy: 53.04%
It appears that all the pre-processing methods boost AUC, at least in validation. The code is available on GitHub.