Can you recognize users of mobile devices from accelerometer data? It’s a rather non-standard problem (we’re dealing with time series here) and an interesting one. So we wrote some code and ran EC2 and then wrote more and ran EC2 again. After much computation we had our predictions, submitted them and achieved AUC = 0.83. Yay! But there’s a twist to this story.
An interesting thing happened when we mistyped a command. Instead of computing AUC from a validation test set and raw predictions, we computed it using a training set:
auc.py train_v.vw r.txt
And got 0.86.
Now, the training file has a very different number of lines from the test file, but our script only cares about how many lines are in a predictions file, so as long as the other file has at least that many, it’s OK.
Turns out you can use this set or that set and get pretty much the same good result with each. That got us thinking. We computed a mean of predictions for each device. Here’s the plot:
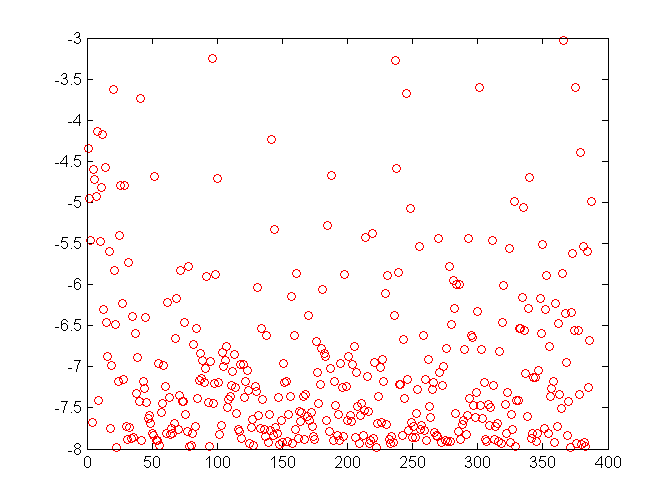
And here’s a histogram of mean predictions:

It looks much like a histogram of number of samples per device (truncated at 100k samples for clarity):
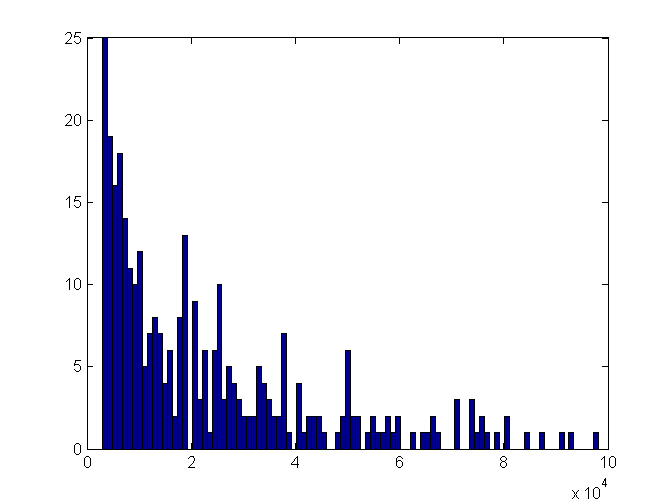
Catching our drift? Let’s just count samples then:
count_samples.py train.csv samples_per_device.csv
And when asked about a device in the test set, we’ll output a probability proportional to the number of samples, so that devices with more samples get bigger outputs:
predict_constants.py questions.csv samples_per_device.csv answers.csv
The score? 0.8. Go beat the benchmark.
Code is available at Github.