You’ve heard about running things on a graphics card, but have you tried it? All you need to taste the speed is a Nvidia card and some software. We run experiments using Cudamat and Theano in Python.
GPUs differ from CPUs in that they are optimized for throughput instead of latency. Here’s a metaphor: when you play an online game, you want fast response times, or low latency. Otherwise you get lag. However when you’re downloading a movie, you don’t care about response times, you care about bandwidth - that’s throughput. Massive computations are similiar to downloading a movie in this respect.
The setup
We’ll be testing things on a platform with an Intel Dual Core CPU @3Ghz and either GeForce 9600 GT, an old card, or GeForce GTX 550 Ti, a more recent card. See the appendix for more info on GPU hardware.
Software we’ll be using is Python. On CPU it employs one core*. That is OK in everyday use because while one core is working hard, you can comfortably do something else because there’s another core sitting idle. If you have four or more cores, that’s another - somewhat wasteful - story.
Actually, sometimes you can use all your cores, for example in scikit-learn’s random forest, thanks to joblib. It only requires writing your script in if __name__ == __main__: main() style.
CUDA development environment
The first thing we need is Nvidia’s CUDA Toolkit, available for an operating system of your choosing. CUDA 5 toolkit is quite large, about 1GB before unpacking, so you need a few GB free space on your hard disk.
Apparently there was a lot of changes from CUDA 4 to CUDA 5, and some existing software expects CUDA 4, so you might consider installing that older version. We ran the tests below with CUDA 5.
Installing Cudamat
As Python CUDA engines we’ll try out Cudamat and Theano. Essentially they both allow running Python programs on a CUDA GPU, although Theano is more than that.
Cudamat is a Toronto contraption. It is also a base for gnumpy, a version of numpy using GPU instead of CPU (at least that’s the idea).
We’ll be installing Cudamat on Windows. The original source needs some adjustments, fortunately there is a version for Windows.
The build process is make-based. We have Cygwin installed so that’s no problem. Apparently you can also build the software using Visual Studio and nmake: INSTALL.txt.
Now put the cudamat dir in PYTHONPATH and you’re good to go. On Windows you go to Advanced System Properties (by pressing Windows+Pause/Break, for example) and then to Environment Variables.
On Unix you could add something like this to your .bashrc:
export PYTHONPATH=$PYTHONPATH:/your/cudamat/dir
Running Cudamat
You can compare CPU/GPU speed by running RBM implementations for both provided in the example programs. On our setup, times per iteration are as follows:
- CPU: 160 seconds
- GeForce 9600 GT: 27 seconds (six times faster)
- GeForce GTX 550 Ti: 8 seconds (20 times faster than a CPU)
Running Theano
To benchmark Theano, here are some outputs from Deep Stochastic Networks, a recent invention from Yoshua Bengio’s camp. Notice the training times per iteration.
On CPU - just one iteration:
1 Train : 0.607190 Valid : 0.367003 Test : 0.364955
time : 1154.125 MeanVisB : -0.22521 W : ['0.024064', '0.022429']
On GeForce 9600 GT:
1 Train : 0.607190 Valid : 0.366969 Test : 0.364927
time : 249.7970 MeanVisB : -0.22521 W : ['0.024064', '0.022429']
2 Train : 0.307378 Valid : 0.276123 Test : 0.276906
time : 274.4370 MeanVisB : -0.32654 W : ['0.023890', '0.022527']
3 Train : 0.291806 Valid : 0.270688 Test : 0.271469
time : 255.9530 MeanVisB : -0.38926 W : ['0.023901', '0.022562']
On GeForce GTX 550 Ti:
1 Train : 0.607192 Valid : 0.367054 Test : 0.364999
time : 53.84399 MeanVisB : -0.22522 W : ['0.024064', '0.022429']
2 Train : 0.302401 Valid : 0.277827 Test : 0.277751
time : 54.53100 MeanVisB : -0.32510 W : ['0.023878', '0.022519']
3 Train : 0.292427 Valid : 0.267693 Test : 0.268585
time : 53.73399 MeanVisB : -0.38779 W : ['0.023884', '0.022551']
Even on the old card training is roughly five times faster than on a CPU. The more recent card is four times faster than that and 20 times faster than a CPU.
One thing to note: in this case Theano takes quite a while - a few minutes - to compile its CUDA programs. That seems to be the rule.
Conclusion
On our rig, a GPU seems to be 20 times faster than a somewhat older CPU. There are already quite a few CUDA-capable machine learning toolkits, mainly for neural networks and SVM, and we think that more are coming. Here are a couple. Neural network libraries are mostly in Python and SVM packages in C/Matlab:
- pylearn - a similiar thing from Lisa Lab in Montreal
- Torch - a well established library for neural networks in Lua
- cuda-convnet - a popular fast C++ implementation of convolutional/feed-forward neural networks (controlled from Python)
- deepnet, by Nitish from Toronto - various neural networks
- CUV - another NN library
- nnForge, a C++ library for training convolutional and fully-connected neural networks. The author does very well in Kaggle competitions.
- Caffe is a framework for convolutional neural network algorithms, developed with speed in mind.
Recently convnets became very popular, here’s a new crop:
- April-ANN: a neural networks toolkit in Lua, including auto-encoders and CNN
- TorontoDeepLearning’s convnet in C/C++. Config in text files.
SVM packages:
- GPUMLib - a C++ library with NN, SVM and matrix factorization
- GTSVM - A GPU-Tailored Approach for Training Kernelized SVMs
- cuSVM - A CUDA Implementation of Support Vector Classification and Regression in C/Matlab
- GPUSVM - another CUDA SVM package
- GPU-LIBSVM - GPU-accelerated LIBSVM for Matlab
Notably missing were any open source tree ensemble packages, but recently one appeared: CudaTree. See Training Random Forests in Python using the GPU.
Appendix: Choosing a Nvidia GPU
If you want CUDA, you need a Nvidia card. They have a few product lines: gaming cards, professional cards, mobile cards, high-end cards, etc. You might wonder which one you should be interested in. And the answer is that GeForce gaming cards offer the best value for money. This is confirmed by John Owens, a lecturer in the Udacity parallel programming (read: CUDA programming) course. He’s a professional and he says that they don’t bother with professional or high-end cards, they use GeForce.
Current mainstream GeForce include GTX 500 and GTX 600 series. 500’s architecture is called Fermi, 600’s - Kepler. Generally the feeling is that Fermi is better for computation as Kepler is optimized for gaming. Here’s a quote from Alex Krizhevsky, the author of cuda-convnet:
Newer (Kepler) GPUs also will work, but as the GTX 680 is a terrible, terrible GPU for non-gaming purposes, I would not recommend that you use it. (It will be slow).
Also see these posts for anecdotal evidence:
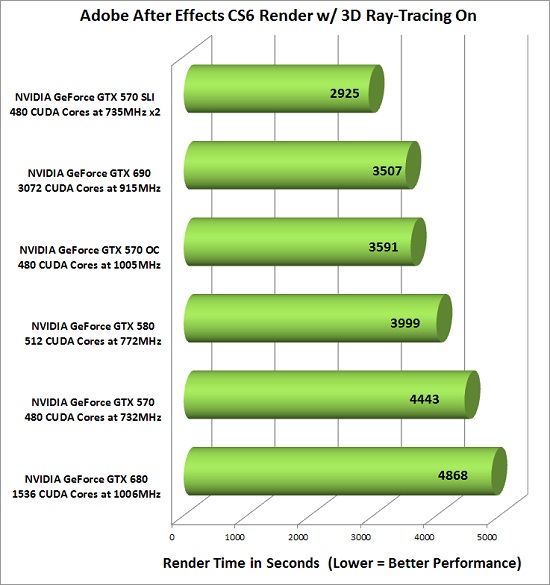
A benchmark from legitreviews.com
If you want more numbers, here are some results from gpugrid.net forum (GPUGRiD.net is a distributed computing infrastructure devoted to biomedical research). They include training time and CPU usage.
Long runs on GeForce 600 series GPU's, Windows app
GPU Computation time (minutes) (min - max) CPU usage (min-max)
NVIDIA GeForce GTX 650 1,725.0 (1,622.7-2,047.0) 99.2% (98.6%-99.6%)
NVIDIA GeForce GTX 650Ti 1,237.7 (518.5-1,914.5) 91.7% (58.8%-99.9%)
NVIDIA GeForce GTX 660 784.6 (352.9-1,045.9) 97.3% (47.6%-100.3%)
NVIDIA GeForce GTX 660Ti 659.5 (312.9-1,348.0) 99.2% (83.0%-102.4%)
NVIDIA GeForce GTX 670 593.9 (455.3-992.8) 98.6% (90.7%-100.2%)
NVIDIA GeForce GTX 680 595.8 (471.4-899.8) 98.4% (80.3%-101.2%)
Long runs on GeForce 500 series cards Windows app
NVIDIA GeForce GTX 550Ti 1,933.7 (1,510.4-2,610.4) 14.8% (3.0%-23.3%)
NVIDIA GeForce GTX 560 1,253.3 (1,090.0-1,820.8) 20.3% (6.0%-27.3%)
NVIDIA GeForce GTX 560Ti 1,001.7 (710.2-2,011.6) 18.4% (6.4%-37.1%)
NVIDIA GeForce GTX 570 870.6 (691.5-1,743.7) 20.2% (5.5%-36.3%)
NVIDIA GeForce GTX 580 711.0 (588.8-1,087.6) 18.8% (9.2%-32.5%)
For these guys, 600 tends to be faster. However note the CPU usage - very high for 600 series, low for 500 series.
The downside of 500 series compared to 600 is high energy consumption. From 560 upwards the cards have a double power connector. A system with GTX 580 in full swing might consume nearly 600W. That means that you need a quite big power supply unit.

Image credit: http://www.legitreviews.com/article/1572/14/