Recently a number of famous people, including Bill Gates, Stephen Hawking and Elon Musk, warned everybody about the dangers of machine intelligence. You know, SkyNet. Terminators. The Matrix. HAL 9000. (Her would be OK probably, we haven’t seen that movie.) Better check that AI, then, maybe it’s the last moment to keep it at bay.
State of the AIt
Real stupidity beats artificial intelligence every time. - Terry Prachett
The current media bubble about machine superintelligence is at least partially based on the belief that true AI is just around a corner. After all, we’re so advanced already and the progress is only accelerating.

Image credit: Futurama / Joel Veness
Let’s take a look at how advanced we are, really. Two representative and well known examples of the current state of the art are:
- Automatic image annotation using a combination of convolutional and recurrent neural networks
- DeepMind’s deep reinforcement learning for playing Atari games
Image captioning
Around the end of 2014 a few labs almost simultanously published their papers on automatic image captioning. Among them were Microsoft, Google and Baidu from the industry and Stanford, Berkeley and Toronto from academia. Here’s an article with links to those papers.
Andrej Karpathy from Stanford published his code - also implementing the Google method - and there’s his talk on the subject. Stanford and Toronto groups have online demos, we’ll look at them now.
Stanford demo
The Stanford project page shows a bunch of images with captions. The captions are awe-inspiring and every one is correct. This illustrates what we want to convey: that people often cherry-pick when reporting results.
Beyond the frontpage there’s a demo with more images. Many captions are equally good, but a large part is not. Let us pick some examples:

“A red and white bus parked in front of a building”

“A man is sitting on a bench with a dog”
“A woman holding a teddy bear in front of a mirror”
OK, “teddy bear” can be forgiven, given the circumstances. And finally,
“A bunch of bananas are hanging from a ceiling”
Toronto demo
The Toronto group’s “image to text” demo doesn’t look as good as Stanford’s, both in terms of web design and captions. However, you can upload your image and have it annotated.
They have a static demo with many pictures. Each image gets five captions. Let’s take a closer look.

The captions are:
- a group of young girls standing next to each other on the beach
- two young women on the beach
- a young girls standing on the beach while one man wearing a hat
- a couple of girls on the beach
- the two women are on the sand with a little girl
Caption one is impressive. Caption four is correct. The other ones are… not so good. Now for something completely different:

- a young boy has a baby in his mouth
- a baby being held by a boy in his mouth
- a baby smiles with his mother
- a baby boy in a pen with mouth
- a young boy is smiling at a baby
To sum up, CNN+RNN technology doesn’t understand numbers or colors. It doesn’t understand meaning of words. It’s nowhere near a real AI - probably closer to ten thousand monkeys striking keys at random in an attempt to replicate Shakespeare’s works.
DeepMind’s DQN
The second paper about world-famous Atari playing Deep-Q Network found its way into Nature. DQN belongs in reinforcement learning, which differs from “normal” machine learning in that there are actions and feedback. An agent observes the world, makes a decision, acts, and the loop repeats. DQN “sees” the screen and moves a simulated joystick. This chart shows how it does, compared to humans.
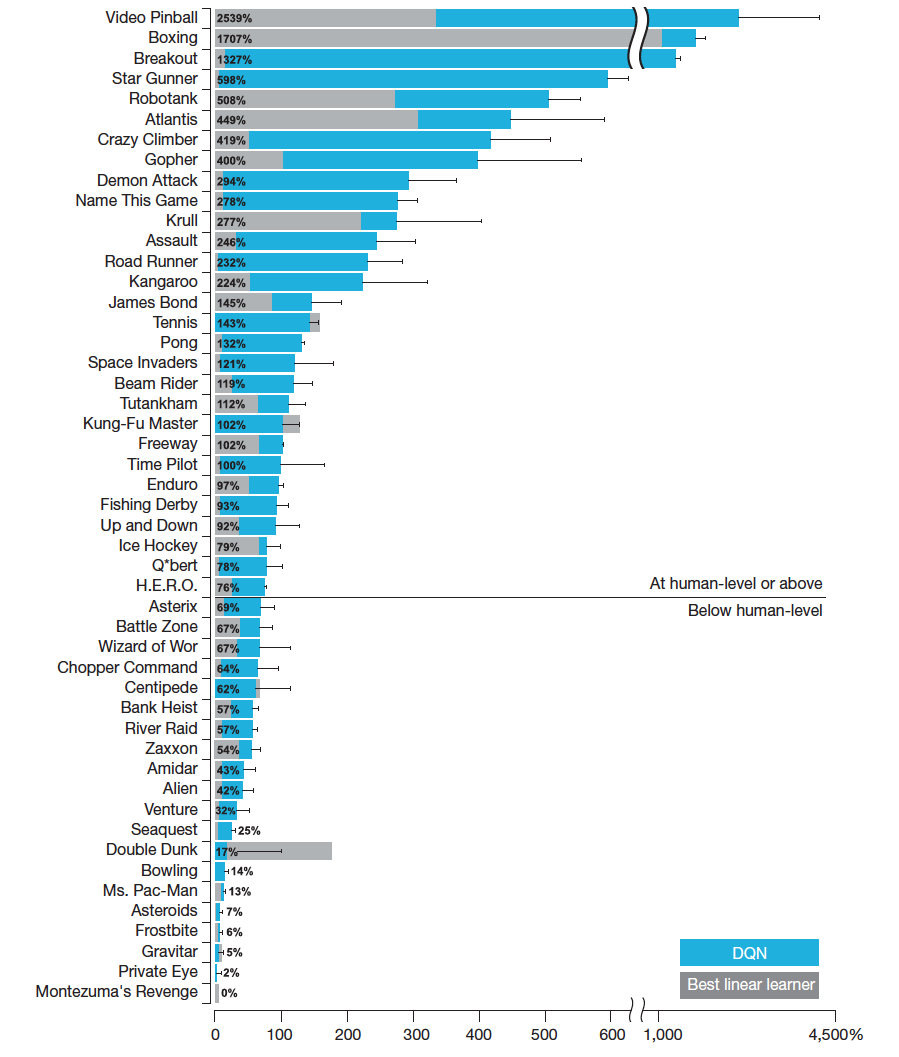
Image credit: Google Research Blog
Google says that
in more than half the games, it performed at more than 75% of the level of a professional human player.
100% seems like a natural choice for the threshold. Why 75%? Well, it’s convenient. If we set the threshold at 100%, DQN is below in more than half of the cases.
Also notice that in four of the top six AI games, a simple linear benchmark is already much better than a human player.
More cherry picking
You might have seen a demo of Breakout and heard the story of how the AI learns to dig a tunnel:
In certain games, DQN even came up with surprisingly far-sighted strategies that allowed it to achieve the maximum attainable scorefor example, in Breakout, it learned to first dig a tunnel at one end of the brick wall so the ball could bounce around the back and knock out bricks from behind.
Apart from that, there’s Space Invaders. Have you seen DQN playing any other games? No? That’s because there are no other videos. Come to think of it, it’s remarkable: that much publicity, “human-level control” and only two short videos, out of 49 games…
Also, Google released the DQN code, but didn’t include trained models. So sure, you can replicate their results and see some action - if you have the skills and a month or two of GPU time.
Some PacMan
Put bluntly, it seems to us that DeepMind AI sucks badly at roughly half the games. There’s an article on why it stinks at PacMan:
The classic game Ms. Pac-Man neatly illustrates the softwares greatest limitation: it is unable to make plans as far as even a few seconds ahead. That prevents the system from figuring out how to get across the maze safely to eat the final pellets and complete a level. It is also unable to learn that eating certain magic pellets allows you to eat the ghosts that you must otherwise avoid at all costs.
No video either, but one of the many authors of the Nature paper, Joel Veness, earlier implemented something called a Monte-Carlo AIXI approximation. What is AIXI?
Jrgen Schmidhuber, a former advisor of a few DeepMind folks, said this in his Reddit AMA:
I think Marcus Hutters AIXI model of the early 2000s was a game changer. (…) Marcus proved that there is a universal AI that is mathematically optimal in a certain sense. Its not a practical sense, otherwise wed probably not even discuss this here. But this work exposed the ultimate limits of both human and artificial intelligence, and brought mathematical soundness and theoretical credibility to the entire field for the first time. These results will still stand in a thousand years.
For now, let’s watch a video of AIXI approximation playing PacMan.
UPDATE: There’s a Theano-based implementation of Deep Q-learning and you can see it play a few games in DeepMind’s Atari paper replicated.
UPDATE: Another implementation, using Chainer. This video shows the network playing Pong.
UPDATE: A video of DQN playing Montezuma Revenge with a commentary of how it fails because of a delayed reward. There’s no direct intermediate feedback so the network doesn’t know when it’s doing well, while for a human it’s obvious.
Post Scriptum
Nothing much to see here, just a normal, inconsequential image. Probably a cat or something.

Continue to part II of this post.