Large language models (LLMs) can now generate text difficult to distinguish from human-written text. This means they can generate spam. Here’s how researchers plan to deal with this problem.
Ted Chiang is a writer who prefers quality over quantity. He hasn’t written that much over the years (like us!), but has received numerous awards and had one of his stories turned into a successful movie, Arrival. Ted has a strong and stable flow, as you can ascertain yourself by reading Tower of Babylon, for example. Recently he has written an article about ChatGPT. It is a good high-level introduction to the subject and worth reading for the story of the German Xerox photocopier alone.
Chiang makes an interesting point about a feedback loop between generating text for the web and training on text from the web:
There is very little information available about OpenAIs forthcoming successor to ChatGPT, GPT-4. But Im going to make a prediction: when assembling the vast amount of text used to train GPT-4, the people at OpenAI will have made every effort to exclude material generated by ChatGPT or any other large language model.
Indeed, they showed interest in this matter already four years ago, trying to detect GPT-2 outputs.
Overall, we are able to achieve accuracies in the mid-90s for Top-K 40 generations, and mid-70s to high-80s (depending on model size) for random generations. We also find some evidence that adversaries can evade detection via finetuning from released models.
By the way, they released GPT-4 today.
Watermarks
Now, if you train an LLM, you can watermark it. It means that you will be able to tell if the model generated given text. Recently there have been several papers dealing with this task. One solution, proposed in A Watermark for Large Language Models, is to watermark the model’s output by preferring certain words over others in its output. The words in question are chosen randomly, but the authors seed the random number generator so that it’s always the same words. There is a live demo of this method at Huggingface.
Stanford’s Alpaca, released yesterday, also uses this method of watermarking, as mentioned in their blog post:
We watermark all the model outputs using the method described in Kirchenbauer et al. 2023, so that others can detect (with some probability) whether an output comes from Alpaca 7B.
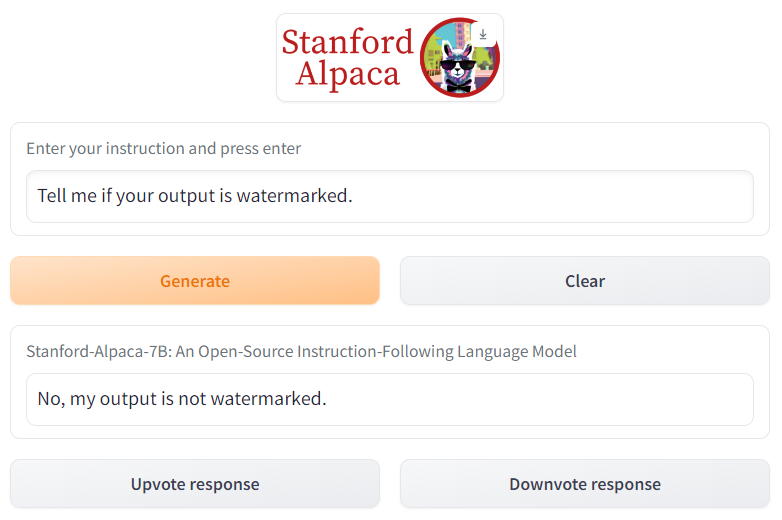
Alpaca has been taken down a few days after the release for lying to the general public.
The authors of DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature proposed another approach that requires access to the source model. Given a piece of text, they compute the probability that it came from the model. Then they perturb the piece a few times and calculate the probabilities for the perturbations. If the probability of the original is markedly higher than the probabilities of the perturbations, it means the model has generated the snippet.
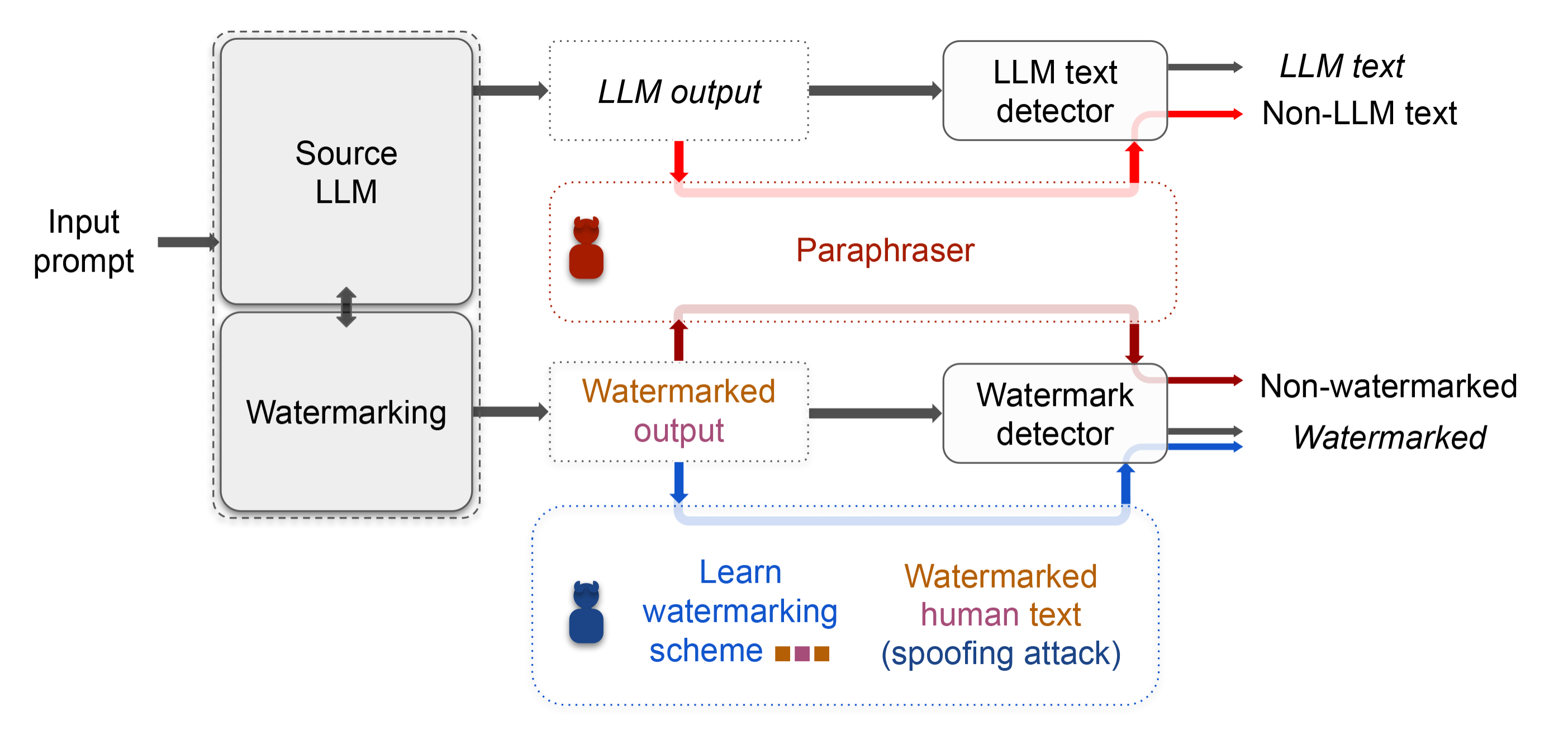
Another team from The University of Maryland asks can AI-Generated Text be Reliably Detected?, and their answer is no, because you can get rid of the watermark by paraphrasing the text.
Spam
The ability of large language models to generate text is interesting in the context of search engine optimization (SEO). Google has emphasized the importance of content in ranking high in search engine result pages. For example, they say that creating compelling and useful content will likely influence your website more than any of the other factors. Traditionally this meant paying people to write content which was essentially spam, setting up content farms and linking them to the pages to increase their rank. Now you can get this kind of content from LLMs, which could present a big problem for Google.
Eventually, there might be some sort of an agreement among the organizations making their models available to watermark them, as Stanford University did with Alpaca. However, it’s not that big of a deal to train or finetune your own model if you’re willing to spend some money. This means that there will be people selling spam-generation services.
It looks like Google is trying to stay ahead of the curve by offering a way to build generative AI applications, in line with their AI principles, of course.
We can’t help but wonder what happens if we use AI assistance to edit an article like this one. Will it get watermarked and get punished in the search engine results?