We continue with CIFAR-10-based competition at Kaggle to get to know DropConnect. It’s supposed to be an improvement over dropout. And dropout is certainly one of the bigger steps forward in neural network development. Is DropConnect really better than dropout?
TL;DR DropConnect seems to offer results similiar to dropout. State of the art scores reported in the paper come from model ensembling.
Dropout
Dropout, by Hinton et al., is perhaps a biggest invention in the field of neural networks in recent years. It adresses the main problem in machine learning, that is overfitting. It does so by “dropping out” some unit activations in a given layer, that is setting them to zero. Thus it prevents co-adaptation of units and can also be seen as a method of ensembling many networks sharing the same weights. For each training example a different set of units to drop is randomly chosen.
The idea has a biological inspiration. When a child is conceived, it receives half its genes from each parent. Because of this the genes cannot rely on a presence of any other particular genes and it forces them to be useful on their own and play well with unknown others.
Dropout is known to work well, although not always:
In vision tasks, input features are commonly dense, while in our task input features are sparse and labels are noisy. In the dense setting, dropout serves to separate effects from strongly correlated features, resulting in a more robust classifier. But in our sparse, noisy setting adding in dropout appears to simply reduce the amount of data available for learning.
DropConnect
DropConnect by Li Wan et al., takes the idea a step further. Instead of zeroing unit activations, it zeroes the weights, as pictured nicely in Figure 1 from the paper:
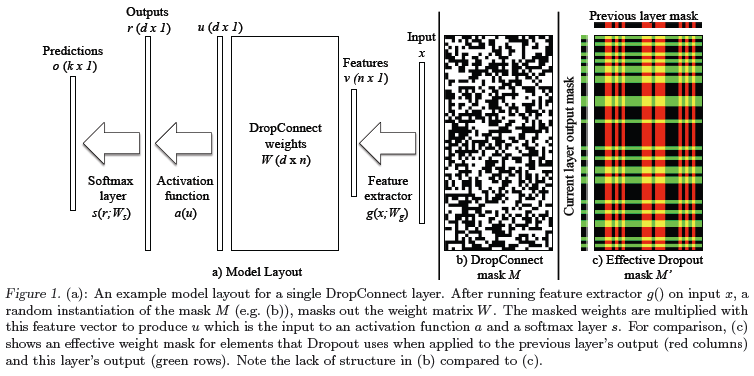
The main difference is that the binary mask is irregular, while for dropout it’s formed of interlocking horizontal stripes from one layer and vertical stripes from the other layer.
The interesting thing about DropConnect is that it’s currently state of the art in many deep learning classification tasks, for example on CIFAR-10.
Previous state-of-the-art is 9.5% (Snoek et al., 2012). Voting with 12 DropConnect networks produces an error rate of 9.32%, signiffcantly beating the state-of-the-art. [Li Wan et al.]
The details
We looked at this closer and found out that DropConnect’s good result on CIFAR comes mainly from model ensembling. The authors train 12 models. Each of them achieves a testing error of about 11%. But when you put them together by simply averaging their predictions, you get 9.32%.
./model_fc128-dcf-50/run01_pred_mean.mat----Testing Error: 0.1139
./model_fc128-dcf-50/run02_pred_mean.mat----Testing Error: 0.1145
./model_fc128-dcf-50/run03_pred_mean.mat----Testing Error: 0.1096
./model_fc128-dcf-50/run04_pred_mean.mat----Testing Error: 0.1123
./model_fc128-dcf-50/run05_pred_mean.mat----Testing Error: 0.1126
./model_fc128-dcf-50/run06_pred_mean.mat----Testing Error: 0.1117
./model_fc128-dcf-50/run07_pred_mean.mat----Testing Error: 0.1091
./model_fc128-dcf-50/run08_pred_mean.mat----Testing Error: 0.1152
./model_fc128-dcf-50/run09_pred_mean.mat----Testing Error: 0.1137
./model_fc128-dcf-50/run10_pred_mean.mat----Testing Error: 0.1125
./model_fc128-dcf-50/run11_pred_mean.mat----Testing Error: 0.1131
./model_fc128-dcf-50/run12_pred_mean.mat----Testing Error: 0.1092
mean: 11.2283333333 std: 0.19586701838
After combine----Testing Error: 0.0932
From the paper results, DropConnect seems to offer a similiar performance to dropout in terms of accuracy, although the details are somewhat complicated due to a large number of model hyperparameters involved - things such as network architecture and the length of training.
What’s interesting is that both form of regularizations lend themselves to use in ensembles (even though dropout and DropConnect can be seen as ensembles). Ensembling is a computationally-costly but effective way of decreasing test error. Because of these features it’s often used in competitions, probably more often than in “real-life” applications. The simplest for is bagging, or model averaging: you train a bunch of models and average their predictions, as seen above.
For each test example each model outputs a probability for each class. That gives 12 10000x10 matrices. The authors just add them and take argmax of each row to get indexes of the most probable class:
class_indexes = np.argmax( the_matrix, 1 )
At Kaggle
We managed to exactly reproduce the CIFAR-10 error score from the paper on the Kaggle CIFAR-10 leadearboard, obtaining a second place. We used models trained by Li Wei to form predictions for the Kaggle testing set.
Even though the whole exercise felt like a one-time hack, we publish files we modified to get them working for the interested. We suggest comparing them to the originals to find out what the modifications are.
Programmers need to understand that sometimes a program really only needs to run once, on one set of input, with expert supervision.
We would like to thank Li Wan for assistance in getting his code to work.