The paper, X-Sample Contrastive Loss: Improving Contrastive Learning with Sample Similarity Graphs, with Yann LeCun as the last author, is about similarity signals between samples, typically images. The point is to learn good representations (embeddings) by contrasting similar and dissimilar images.
Let’s see how this is usually done. If you have images without any labels, you take an image and augment it, for example by mirror flipping it, or by adding some noise. The original image and the augmented version form a positive pair.
If you have class labels, images from the same class form positive pairs, and images from different classes form negative pairs. Note that both in this case and in the previous case the relations are binary (either positive or negative, no in-between).
Now we get to the essence of the paper. For images with captions, one can encode the captions (they use Sentence-BERT for this) and compute the cosine similarity between them. This measure of similarity, being non-binary, allows for shades of gray.
Coming back to the images with class labels, you can encode the class labels (cat, dog, etc.) instead of captions, and compute the similarity. The idea is that text embeddings for cat and dog will be closer to each other than to house or sky, so again you get shades of gray instead of zero/one.
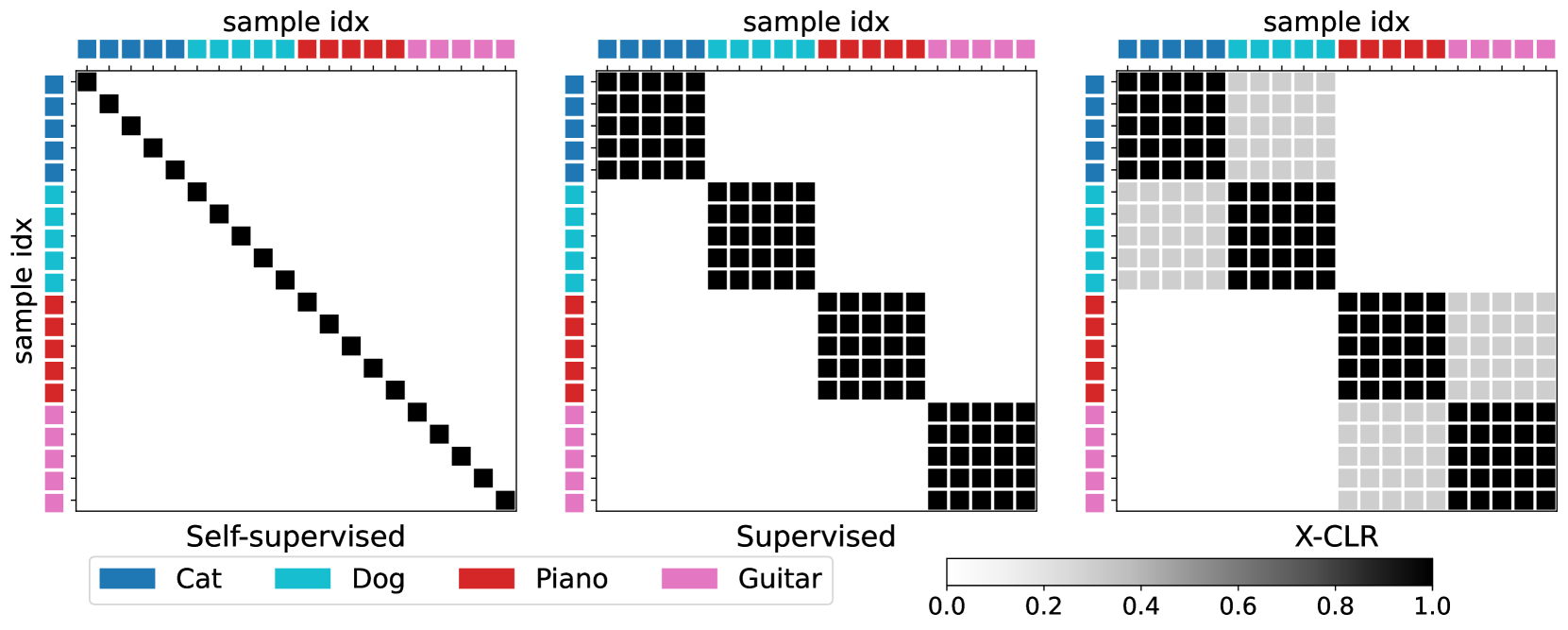
Apparently representations learned in this way are better than competitors (like CLIP) for downstream tasks such as classification, especially with relatively few examples available.