The Black Box challenge has just ended. We were thoroughly thrilled to learn that the winner, doubleshot, used sparse filtering, apparently following our cue. His score in terms of accuracy is 0.702, ours 0.645, and the best benchmark 0.525.
We ranked 15th out of 217, a few places ahead of the Toronto team consisting of Charlie Tang and Nitish Srivastava. To their credit, Charlie has won the two remaining Challenges in Representation Learning.
Not-so-deep learning
The difference to our previous, beating-the-benchmark attempt is twofold:
- one layer instead of two
- for supervised learning, VW instead of a random forest
Somewhat suprisingly, one layer works better than two. Even more surprisingly, with enough units you can get 0.634 using a linear model (Vowpal Wabbit, of course, One-Against-All). In our understanding, that’s the point of overcomplete representations*, which Stanford people seem to care much about.
Recall The secret of the big guys and the paper cited: An Analysis of Single-Layer Networks in Unsupervised Feature Learning, key words here being “single layer”.
Sparse filtering is better than K-means mapping with high-dimensional datasets, because the latter is subject to a curse of dimensionality and works with hundreds of features, tops.
The take-home point here is that both Chuck Norris and Andrew Ng do their deep learning with one layer (Chuck Norris always, Andrew Ng sometimes).
How we did it
To produce our best submission we selected some features using mRMR and fed them to a small feed-forward neural network, actually in Vowpal Wabbit too. Consider this for a moment: a neural network in Vowpal Wabbit. That’s an amazing feat and a subject for a separate post.
Specifically, we took 400-dimensional data from sparse filtering and selected 100 features using MaxRel.
Then we run Vowpal Wabbit in a “neural network” mode with 20 hidden units:
vw -d train.vw -k -c -f model --passes 100 --oaa 9 --nn 20
vw -t -d test.vw -k -c -i model -p p.txt
If we wanted to run just a linear model, the training command would be:
vw -d train.vw -k -c -f model --passes 100 --oaa 9
Some code is available at Github.
Isn’t more better?
We thought that the more iterations for sparse filtering, the better. So we left the thing running overnight to complete 450 iterations instead of 100 we tried before. And indeed, the value of the objective function went down nicely:
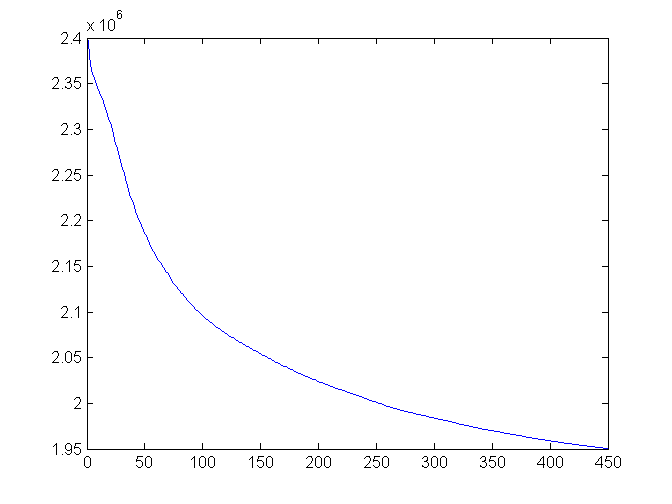
However in supervised stage it turned out that the representation learned with 100 iterations worked significantly better. This is a little disconcerting to us.
A hot topic
Our previous article on deep learning made some splash, as can be seen on this Google Analytics screenshot:

The spike is on May 3, shortly after publishing the post.
*although here we just do big enough; we tried 600 units and 400 was better at 100 iterations.