Python, being a general purpose programming language, lets you run external programs from your script and capture their output. This is useful for many machine learning tasks where one would like to use a command line application in a Python-driven pipeline. As an example, we investigate how Vowpal Wabbit’s hash table size affects validation scores.
Motivation
Some people seem to stick to the native Python tools like scikit-learn, because they offer a comfort of end-to-end solution. On the other hand, command line binaries might be faster and provide functionality not available in Python.
Fortunately the language has utilities for integrating such tools. We’ll take a look at two functions: os.system() and subprocess.check_output(). The main difference between them is that the first doesn’t capture the output of the command, while the latter does. However, with os.system() one can redirect the output to a file and then read from that file, as we demonstrate below.
The downside of both approaches is that you can’t see the output from the external program while it’s running. On Unix there is a way to remedy this: tee. The command prints its input and also writes it to a file, so you get to both see what’s going on and have it logged.
As an example we’ll run Vowpal Wabbit from Python to check how -b option affects the score. The option controls the size of the hash table, and typically higher is better, as small table sizes result in hash collisions.
cmd = 'vw --loss_function logistic --cache_file {} -b {} 2>&1 | tee {}'.format(
path_to_cache, b, tmp_log_file )
os.system( cmd )
output = open( tmp_log_file, 'r' ).read()
This command makes VW read the given cache file as input. With |, we pipe the output to tee, which saves it to tmp_log_file. Then we read it. But what does 2>&1 mean?
I/O streams
Another useful feature of Unix, also partly available on Windows - in a typical half-broken fashion - is the concept of I/O streams: standard input, standard output and standard error. Particularly the split between output and error streams is what interests us. Typically a command line program prints its normal output to stdout and error messages to stderr - this way they don’t get mixed.
Sometimes one would like to combine stdout and stderr into a single stream. The standard streams have their numbers, respectively 0, 1 and 2 for input, output and error. Therefore, to redirect stderr to stdout (as we did above) in a Unix shell you would write:
$ command 2>&1
Note the ampersand in front of 1 - without it, the shell would treat 1 as a file name.
By the way, if you want to redirect both stdout and stderr to a file, there’s a shortcut for that (Unix only):
$ command &>output_file
Now for the check_output() example - it is structured a bit differently, but does the same thing. Note that we don’t need to use the temporary file:
cmd = 'vw --loss_function logistic --cache_file {} -b {} 2>&1'.format(
path_to_cache, b )
output = subprocess.check_output( '{} | tee /dev/stderr'.format( cmd ), shell = True )
On Unix, it is possible to refer to the streams by their filesystem names: /dev/stdin, /dev/stdout and /dev/stderr. In the example above we use a little trick: since the function catches standard output, but not standard error, we tee the output to /dev/stderr so it gets printed on screen while at the same time it goes to standard output and is captured.
The shell argument causes the function to execute a given command using a shell. In practice it means you can pass the arguments as a string, instead of a list, as check_output() would normally expect.
Processing the output
Once we have the output, we can extract the information we want from it. This can be done with regular expressions. They are a language unto themselves, but even a bit of pattern matching gets you a long way.
The thing is, in VW output there is a line with info about average loss, which looks like this:
average loss = 0.052345452
We would like to match that pattern and extract the number, and this function does the trick:
def get_loss( output ):
pattern = 'average loss = (.*?)\n'
m = re.search( pattern, output )
loss = m.group( 1 )
return loss
In short, parentheses in the pattern define a (sub)group which we would like to capture. A dot stands for any character, and an asterisk means “zero or more times”, so .*\n means “any character zero or more times, followed by a newline”. Finally, the question mark makes * non-greedy so that it will stop at the first newline it sees.
When performing multiple passes, VW will indicate using the holdout set for calculating loss:
average loss = 0.052345452 h
To account for this, we cold match only digits, dots and ‘e’ (in case VW happens to print numbers in scientific notation):
pattern = 'average loss = ([0-9.e]+)'
The group we’re extracting is “one or more characters from those within the brackets”. The rest works the same.
Putting it all together
Now that we know how to call VW from Python and extract interesting pieces from its output, let’s plot the error against hash table bits used. We tested a range of 7 to 29 bits on the KDD10B dataset using one pass and no quadratic features:

Average log loss for KDD10b, one pass, no quadratic features
It seems that for this case the optimal number of bits is 25. Bigger values use more memory but don’t improve the score.
Here’s a similiar plot for the Amazon Access Control dataset with quadratic features, many passes and holdout set/early stopping. Apparently there’s little payoff for increasing bits beyond 20.
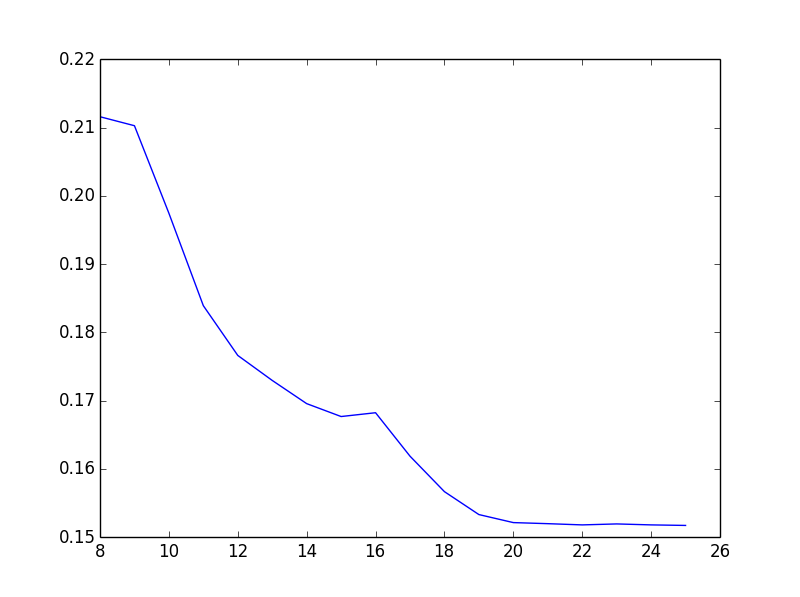
Average log loss for Amazon Access Control dataset, using quadratic features and many passes with early stopping
The code is available at GitHub.
Finally, if you’re specifically interested in running VW from Python, you might check out vowpal_porpoise, Wabbit Wappa or Hal Daume’s pyvw.
UPDATE: Check out the plumbum library, which attempts to make running shell commands from Python easy.