As a wild stream after a wet season in African savanna diverges into many smaller streams forming lakes and puddles, so deep learning has diverged into a myriad of specialized architectures. Each architecture has a diagram. Here are some of them.
Neural networks are conceptually simple, and that’s their beauty. A bunch of homogenous, uniform units, arranged in layers, weighted connections between them, and that’s all. At least in theory. Practice turned out to be a bit different. Instead of feature engineering, we now have architecture engineering, as described by Stephen Merrity:
The romanticized description of deep learning usually promises that the days of hand crafted feature engineering are gone - that the models are advanced enough to work this out themselves. Like most advertising, this is simultaneously true and misleading.
Whilst deep learning has simplified feature engineering in many cases, it certainly hasn’t removed it. As feature engineering has decreased, the architectures of the machine learning models themselves have become increasingly more complex. Most of the time, these model architectures are as specific to a given task as feature engineering used to be.
To clarify, this is still an important step. Architecture engineering is more general than feature engineering and provides many new opportunities. Having said that, however, we shouldn’t be oblivious to the fact that where we are is still far from where we intended to be.
Not quite as bad as doings of architecture astronauts, but not too good either.
An example of architecture specific to a given task
LSTM diagrams
How to explain those architectures? Naturally, with a diagram. A diagram will make it all crystal clear.
Let’s first inspect the two most popular types of networks these days, CNN and LSTM. You’ve already seen a convnet diagram, so turning to the iconic LSTM:
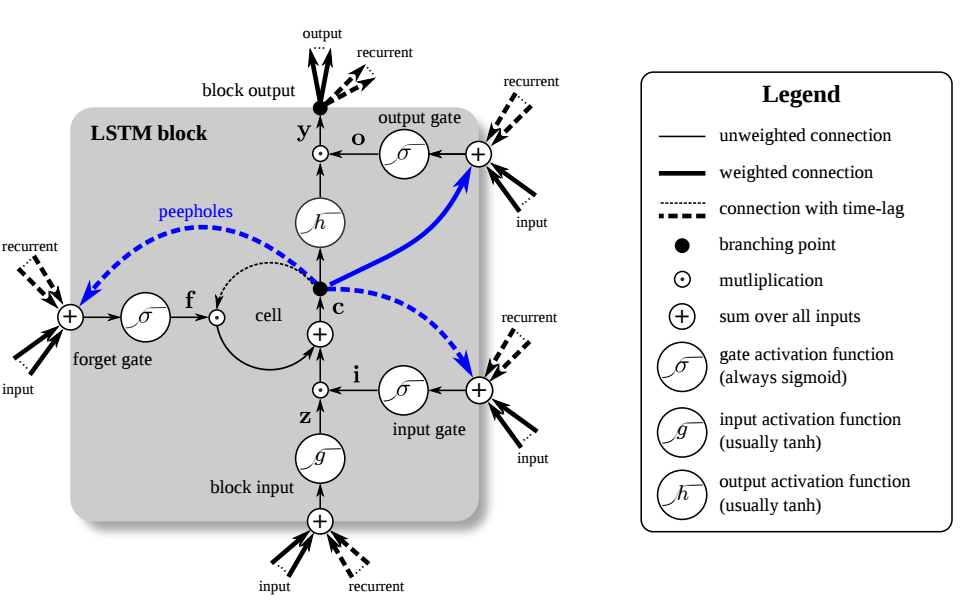
It’s easy, just take a closer look:
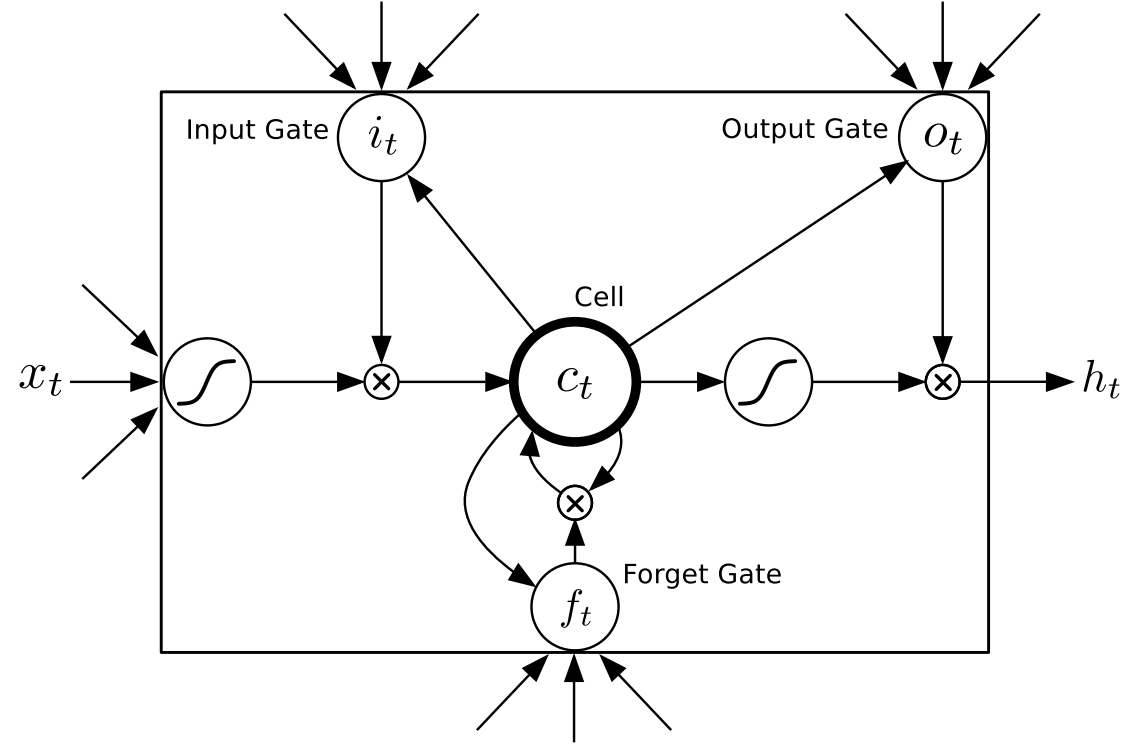
As they say, in mathematics you don’t understand things, you just get used to them.
Fortunately, there are good explanations, for example Understanding LSTM Networks and Written Memories: Understanding, Deriving and Extending the LSTM.
LSTM still too complex? Let’s try a simplified version, GRU (Gated Recurrent Unit). Trivial, really.
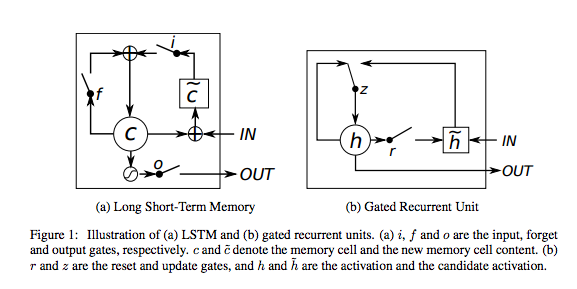
Especially this one, called minimal GRU.
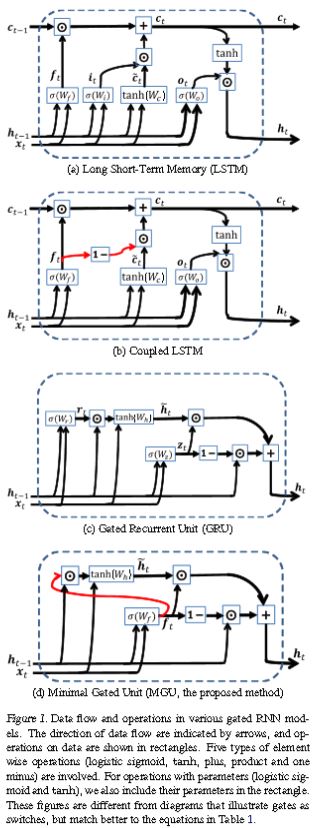
More diagrams
Various modifications of LSTM are now common. Here’s one, called deep bidirectional LSTM:

DB-LSTM, PDF
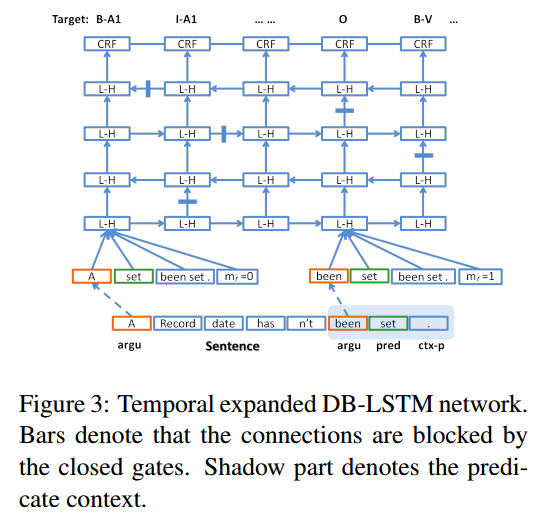
The rest are pretty self-explanatory, too. Let’s start with a combination of CNN and LSTM, since you have both under your belt now:
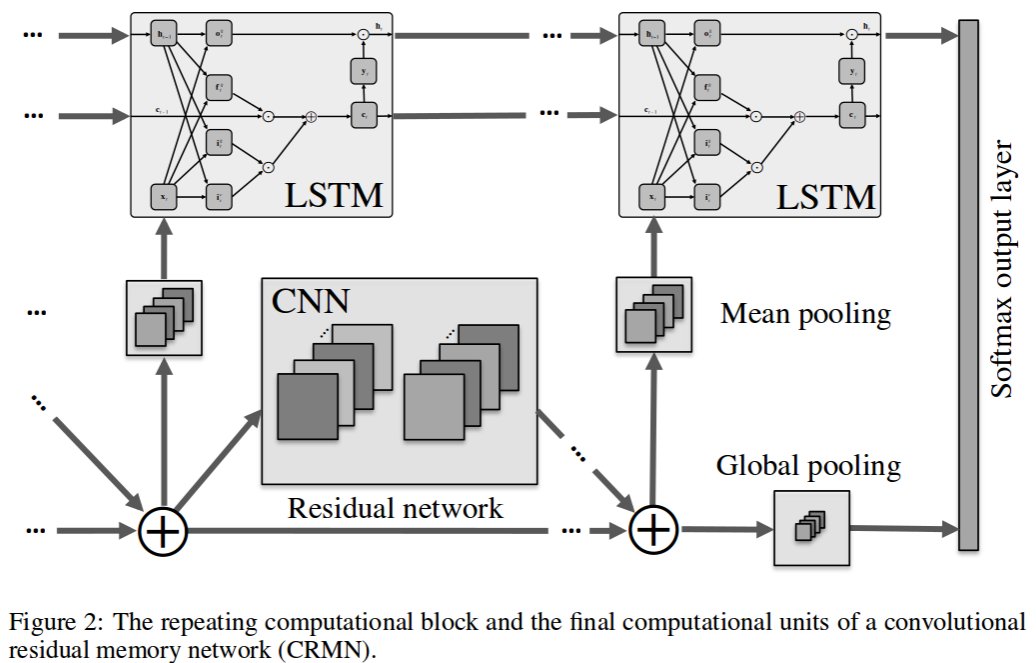
Convolutional Residual Memory Network, 1606.05262
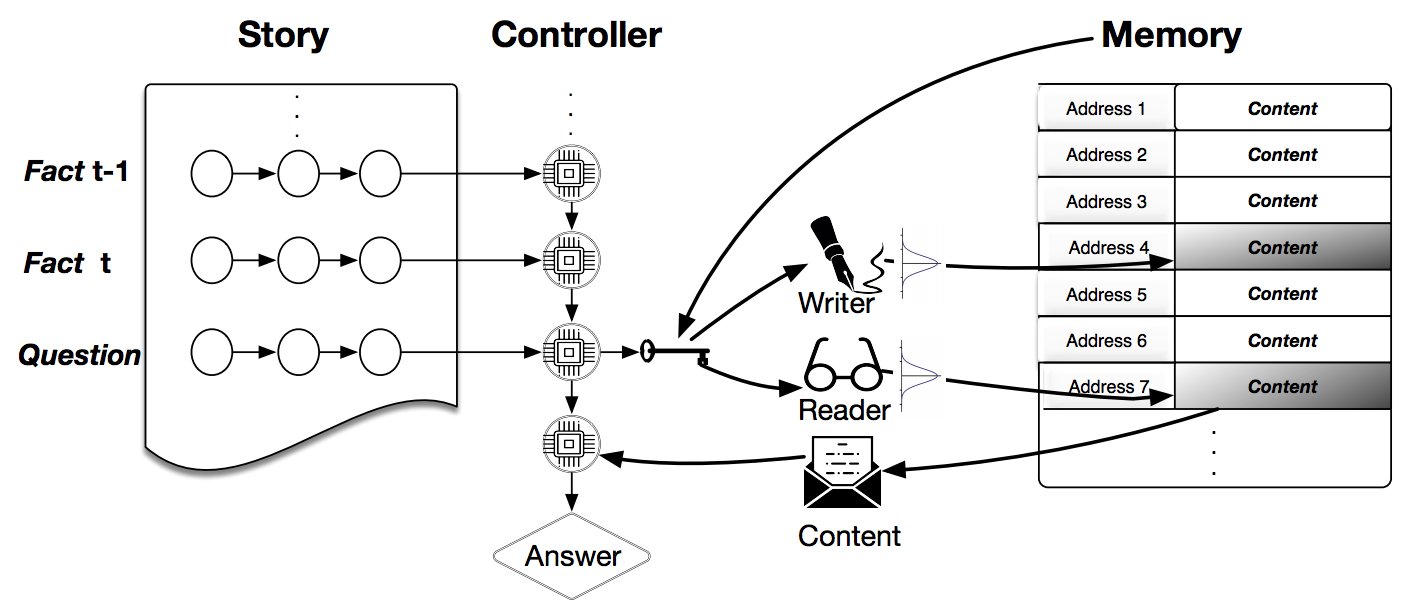
Dynamic NTM, 1607.00036

Evolvable Neural Turing Machines, PDF

Unsupervised Domain Adaptation By Backpropagation, 1409.7495
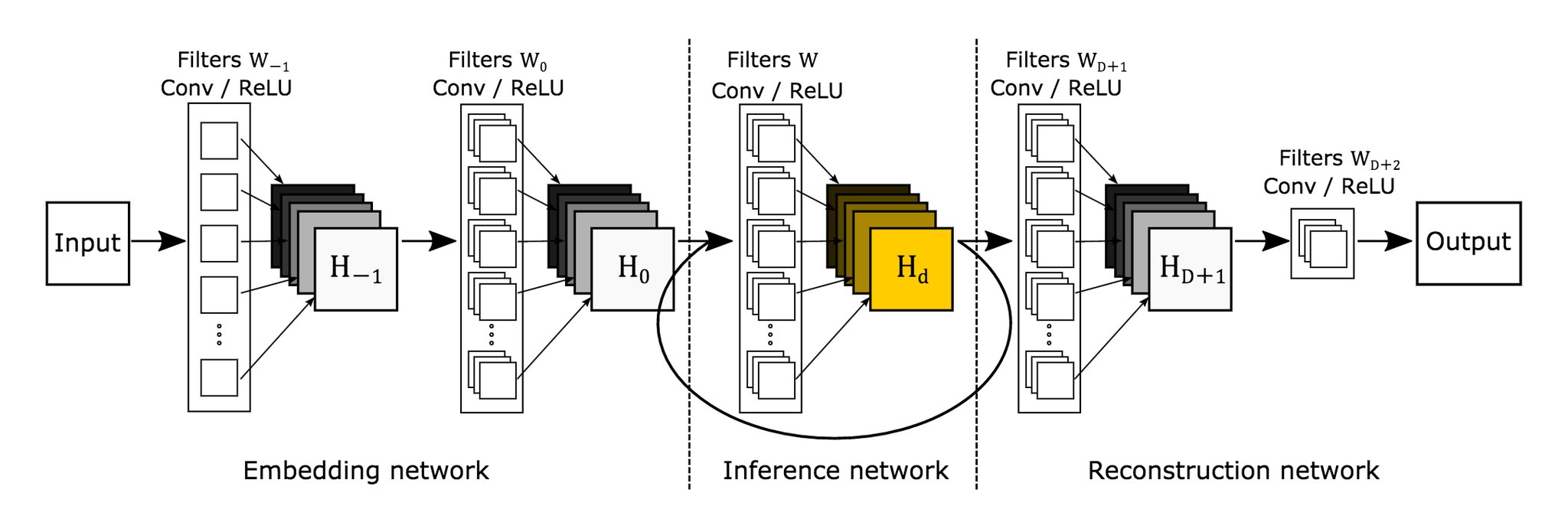
Deeply Recursive CNN For Image Super-Resolution, 1511.04491
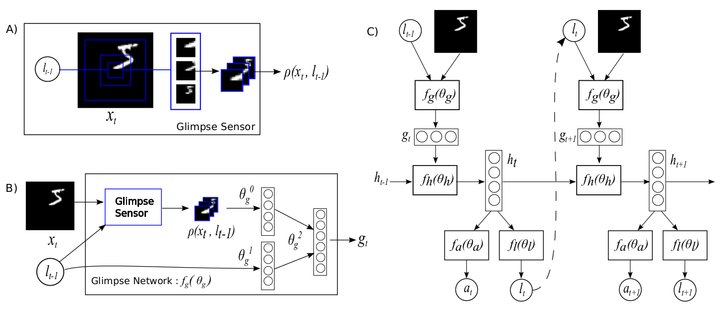
Recurrent Model Of Visual Attention, 1406.6247
This diagram of multilayer perceptron with synthetic gradients scores high on clarity:
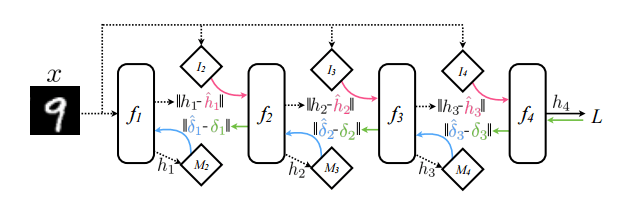
MLP with synthetic gradients, 1608.05343

Every day brings more. Here’s a fresh one, again from Google:
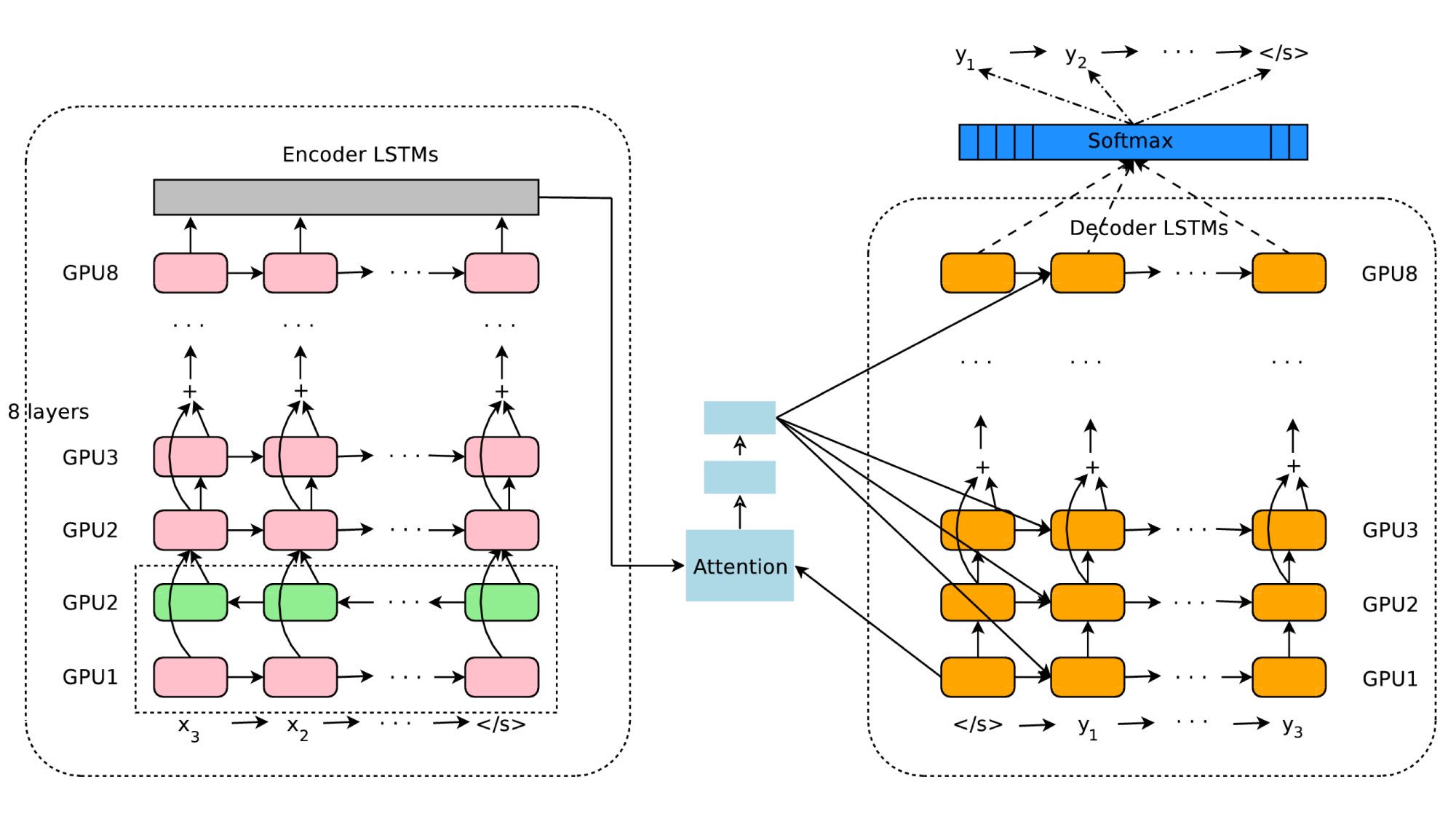
Google’s Neural Machine Translation System, 1609.08144
And Now for Something Completely Different
Drawings from the Neural Network ZOO are pleasantly simple, but, unfortunately, serve mostly as eye candy. For example:


ESM, ESN and ELM
These look like not-fully-connected perceptrons, but are supposed to represent a Liquid State Machine, an Echo State Network, and an Extreme Learning Machine.
How does LSM differ from ESN? That’s easy, it has green neuron with triangles. But how does ESN differ from ELM? Both have blue neurons.
Seriously, while similar, ESN is a recurrent network and ELM is not. And this kind of thing should probably be visible in an architecture diagram.

P.S.
You haven’t seen anything till you’ve seen A Neural Compiler:

The input of the compiler is a PASCAL Program.
The compiler produces a neural network that computes what is specified by the PASCAL program.
The compiler generates an intermediate code called cellular code.
Weird, huh?