There is a Kaggle training competition where you attempt to classify text, specifically movie reviews. No other data - this is a perfect opportunity to do some experiments with text classification.
Kaggle has a tutorial for this contest which takes you through the popular bag-of-words approach, and a take at word2vec. The tutorial hardly represents best practices, most certainly to let the competitors improve on it easily. And that’s what we’ll do.
Validation
Validation is a cornerstone of machine learning. That’s because we’re after generalization to the unknown test examples. Usually the only sensible way to assess how a model generalizes is by using validation: either a single training/validation split if you have enough examples, or cross-validation, which is more computationally expensive but a necessity if you have few training points.
A sidenote: in quite a few Kaggle competitions a test set comes from a different distribution than a training set, meaning it’s hard to even make a representative validation set. That’s either a challenge or stupidity, depending on your point of view.
To motivate the need for validation let’s inspect a case of the Baidu team taking part in the ImageNet competition. These guys apparently didn’t know about validation, so they had to resort to evaluating their efforts using the leaderboard. You only get two submissions a week with ImageNet, so they created a number of fake accounts to broaden their bandwidth. Unfortunately, the organizers didn’t like it and it resulted in an embarassment for Baidu.
Validation split
Our first step is to modify the original tutorial code by enabling validation. Therefore we need to split the training set. Since we have 25k training examples, we will take 5k for testing and leave 20k for training. One way is to split a training file into two - we used the split.py script from phraug2:
python split.py train.csv train_v.csv test_v.csv -p 0.8 -r dupa
Using a random seed “dupa” for reproducibility. Dupa is a Polish codeword for occasions like this. Results we report below are based on this split.
The training set is rather small, so another way is to load the whole training file into memory and split it then, using fine tools that scikit-learn provides exactly for this type of thing:
from sklearn.cross_validation import train_test_split
train, test = train_test_split( data, train_size = 0.8, random_state = 44 )
The scripts we provide use this mechanism instead of separate train/test files, for convenience. We need to use indices cause we’re dealing with Pandas frames, not Numpy arrays:
all_i = np.arange( len( data ))
train_i, test_i = train_test_split( all_i, train_size = 0.8, random_state = 44 )
train = data.ix[train_i]
test = data.ix[test_i]
The metric
The metric for the competition is AUC, which needs probabilities. For some reason the Kaggle tutorial predicts only zeros and ones. This is easy to fix:
p = rf.predict_proba( test_x )
auc = AUC( test_y, p[:,1] )
And we see that random forest scores roughly 91.9%.
Random forest for bag-of-words? No.
Random forest is a very good, robust and versatile method, however it’s no mystery that for high-dimensional sparse data it’s not a best choice. And BoW representation is a perfect example of sparse and high-d.
We covered bag of words a few times before, for example in A bag of words and a nice little network. In that post, we used a neural network for classification, but the truth is that a linear model in all its glorious simplicity is usually the first choice. We’ll use logistic regression, for now leaving hyperparams at their default values.
Validation AUC for logistic regression is 92.8%, and it trains much faster than a random forest. If you’re going to remember only one thing from this article, remember to use a linear model for sparse high-dimensional data such as text as bag-of-words.
TF-IDF
TF-IDF stands for “term frequency / inverse document frequency” and is a method for emphasizing words that occur frequently in a given document, while at the same time de-emphasising words that occur frequently in many documents.
Our score with TfidfVectorizer and 20k features was 95.6%, a big improvement.
Stopwords and N-grams
The author of the Kaggle tutorial felt compelled to remove stopwords from reviews. Stopwords are commonly occuring words, like “this”, “that”, “and”, “so”, “on”. Is it a good decision? We don’t know, we need to check, we have the validation set, remember? Leaving stopwords in scores 92.9% (before TF-IDF).
There is one more important reason against removing stopwords: we’d like to try n-grams, and for n-grams we better leave all the words in place. We covered n-grams before, they are combinations of n sequential words, starting with bigrams (two words): “cat ate”, “ate my”, “my precious”, “precious homework”. Trigrams consist of three words: “cat ate my”, “ate my homework”, “my precious homework”; 4-grams of four, and so on.
Why do n-grams work? Consider this phrase: “movie not good”. It has obviously negative sentiment, however if you take each word in separation you won’t detect this. On the opposite, the model will probably learn that “good” is a positive sentiment word, which doesn’t help at all here.
On the other hand, bigrams will do the trick: the model will probably learn that “not good” has a negative sentiment.
To use a more complicated example from Stanford’s sentiment analysis page:
This movie was actually neither that funny, nor super witty.
For this, bigrams will fail with “that funny” and “super witty”. We’d need at least trigrams to catch “neither that funny” and “nor super witty”, however these phrases don’t seem to be too common, so if we’re using a restricted number of features, or regularization, they might not make it into the model. Hence the motivation for a more sophisticated model like a neural network, but we digress.
If computing n-grams sounds a little complicated, scikit-learn vectorizers can do it automatically. As can Vowpal Wabbit, but we won’t use Vowpal Wabbit here.
The AUC score with tri-grams is 95.9%.
Dimensionality
Each word is a feature: whether it’s present in the document or not (0/1), or how many times it appears (an integer >= 0). We started with the original dimensionality from the tutorial, 5000. This makes sense for a random forest, which as a highly non-linear / expressive / high-variance classifier needs a relatively high ratio of examples to dimensionality. Linear models are less exacting in this respect, they can even work with d >> n.
We found out that if we don’t constrain the dimensionality, we run out of memory, even with such a small dataset. We could afford roughly 40k features on a machine with 12 GB of RAM. More caused swapping.
For starters, we tried 20k features. The logistic regression scores 94.2% (before TF-IDF and n-grams), vs 92.9% with 5k features. More is even better: 96.0 with 30k, 96.3 with 40k (after TF-IDF and ngrams).
To deal with memory issues we could use the hashing vectorizer. However it only scores 93.2% vs 96.3% before, partly because it doesn’t support TF-IDF.
Epilogue
We showed how to improve text classification by:
- making a validation set
- predicting probabilities for AUC
- replacing random forest with a linear model
- weighing words with TF-IDF
- leaving the stopwords in
- adding bigrams or trigrams
The public leadearboard score closely reflects validation score: both are roughly 96.3%. At the time of submission it was good enough for top 20 out of ~500 contenders.
You might remember that we left the logistic regression hyperparams at their default values. Moreover, the vectorizer has its own params, actually more that you would expect. Tweaking both results in a modest improvement, to 96.6%.
Again, code for this article is available on Github.
UPDATE: Mesnil, Mikolov,Ranzato and Bengio have a paper on sentiment classification: Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews (code). They found that a linear model using n-grams outperformed both a recurrent neural network and a linear model using sentence vectors.
However, the dataset they use, the Stanford Large Movie Review Dataset, is small - it has 25000 training examples. Alec Radford says that RNN start to outperform linear models when the number of examples is larger, roughly from 100k to 1M.
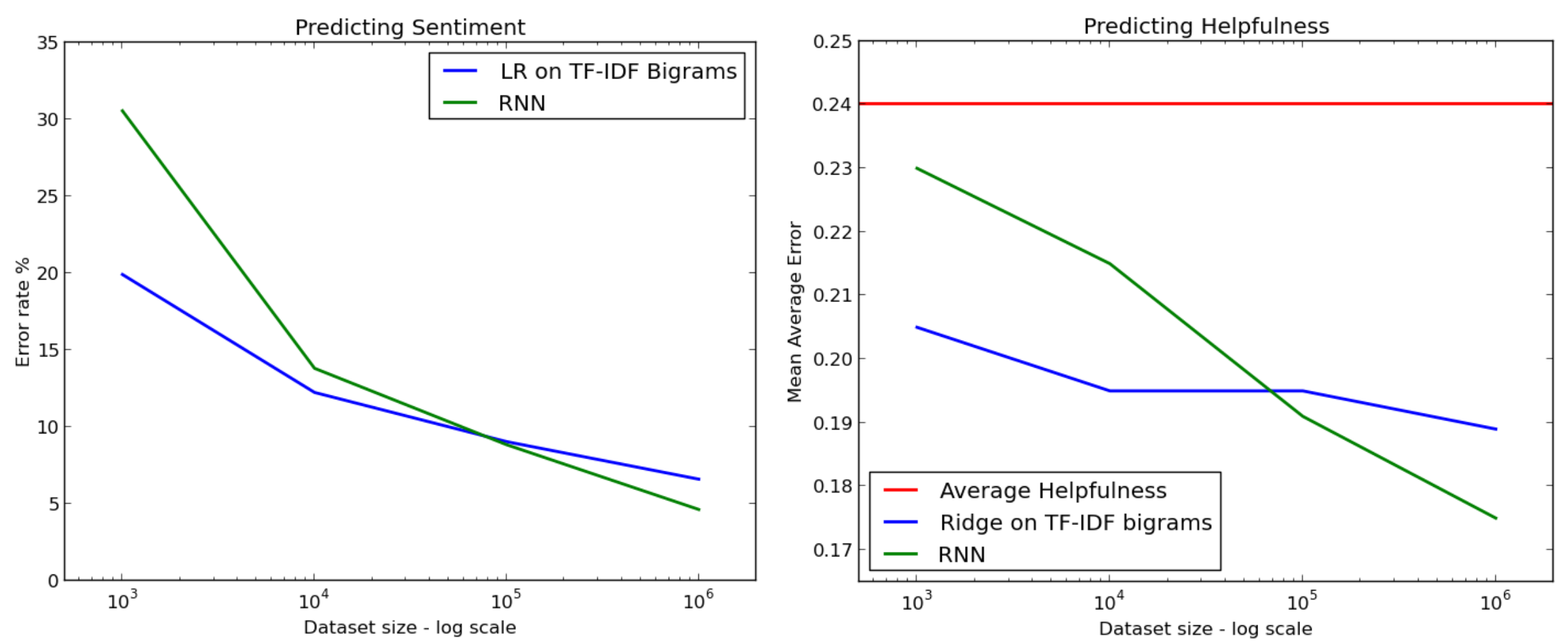
Credit: Alec Radford / Indico, Passage example
As to sentence vectors, the authors use them with logistic regression. We’d rather see the 100-d vectors fed to a non-linear model like random forest.
Having done that, we humbly discovered that random forest scores just 85-86% (strange… why?), depending on the number of trees. Logistic regression yields roughly 89% accuracy, exactly as reported in the paper.
By the way, the version of word2vec supplied in the repository can train sentence vectors (presumably the same as paragraph vectors, since the author of both is Tomas Mikolov).