An overview of key points about big data. This post was inspired by a very good article about big data by Chris Stucchio (linked below). The article is about hype and technology. We hate the hype.
Big data is hype
Everybody talks about big data; nobody knows exactly what it is. That’s pretty much the definition of hype. Google Trends suggest that the term took off at the beginning of 2011 (and the searches are coming mainly from Asia, curiously).
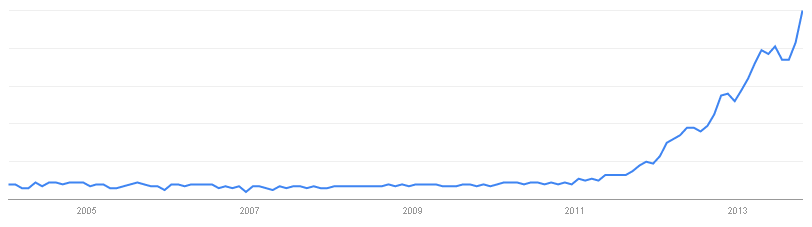
Now, to put things in context:

Big data is right there (or maybe not quite yet?) with other slogans like web 2.0, cloud computing and social media. In effect, big data is a generic term for:
- data science
- machine learning
- data mining
- predictive analytics
and so on. Don’t believe us? What about James Goodnight, the CEO of SAS:
The term big data is being used today because computer analysts and journalists got tired of writing about cloud computing. Before cloud computing it was data warehousing or ‘software as a service’. There’s a new buzzword every two years and the computer analysts come out with these things so that they will have something to consult about. [computing.co.uk]
Also see Most data isn’t big, and businesses are wasting money pretending it is and a paper from Microsoft: Nobody ever got fired for buying a cluster.

Another way to say it: big data is like a teenage sex… You already know this meme, don’t you?
Big data is technical difficulty
Big data can be defined in terms of technical difficulty it causes. For example, when deciding if your data is big, you could draw a line on whether it fits comfortably* into memory. Of course there are computers with 2GB of RAM and there are those with 256GB of RAM, so it’s not a strict distinction. The point is, as data grows larger it becomes more difficult to process it.
Here’s a quote from Chris Stucchio’s article. The author is talking about Map Reduce:
The only reason to put on this straightjacket is that by doing so, you can scale up to extremely large data sets. Most likely your data is orders of magnitude smaller. But because “Hadoop” and “Big Data” are buzzwords, half the world wants to wear this straightjacket even if they don’t need to.
The moral is: don’t make your data bigger than it needs to be.
*comfortably, because after loading there’s processing, so you need even more memory for that.
Big data is effective
If it’s hype and a source of difficulties, why bother? Because apparently it’s effective, as pointed out by Halevy, Norvig and Pereira in The Unreasonable Effectiveness of Data [PDF]:
in 2006, Google released a trillion-word corpus (…) In some ways this corpus is a step backwards from the Brown Corpus: it’s taken from unfiltered Web pages and thus contains incomplete sentences, spelling errors, grammatical errors, and all sorts of other errors. It’s not annotated with carefully hand-corrected part-of-speech tags. But the fact that it’s a million times larger than the Brown Corpus outweighs these drawbacks.
Here’s a corresponding talk by Peter Norvig.
In machine learning, particularly, more examples usually is better, especially when data dimensionality is high. For example, suppose we’re dealing with 1000 dimensions. If you have 1000 examples, good luck. If you have 100000 examples, no big deal. This is important because data often is high-dimensional (and sparse, meaning a lot of zeroes). Which brings us to the last point…
Big data is spying
Consider a task the big guys like Google, Facebook etc. are dealing with: they have visitor data from hundreds of thousands or millions or n sites. Those sites form columns - each site is one dimension. You (or your browser, depending how you look at it), among other people, are a row in that data: for sites you have visited the value in the appropriate column is one, or maybe a count. For all others it’s zero. This is big data. Welcome to the Matrix!
And then there’s NSA, but that’s another story.
P.S. The US companies have been rather quiet about the NSA scandal. In November, Apple and Google have made their moves. Apple published a transparency report, notable for its, let’s say, tagline: our business does not depend on collecting personal data. Well, try creating your Apple ID. For a company not interested in personal data they’re pretty nosy, aren’t they? And Google announced encrypting its internal network. Whether it works or not, a good PR stunt.